
В 1970х и 1980х годах британскими учеными (как бы забавно это ни звучало), Стивеном Робертсоном и Карен Спар Джоунс, был разработан вероятностно-поисковой механизм. Их труды легли в основу bm25, алгоритма ранжирования, о котором мы сегодня поговорим. Суть функции заключается в определении релевантности документа к поисковому запросу. Т. е. документ анализируется, значения проставляются в формулу, где идет расчет относительно других документов в коллекции и выдается некая конечная оценка, которая влияет на ранжирование документа в поисковой выдаче. Сложновато.
Данную функцию еще часто называют «Okapi bm25», в честь поисковой системы, которая была создана в Лондонском городском университете в 1980х, 1990х годах.
Как ведется расчет
Пусть задан запрос Q, который содержит слова q1…qn. В таком случае бм 25 выдает нам оценку релевантности документа В к запросу Q:
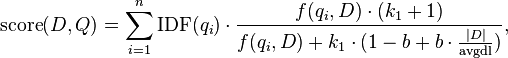
Мы не будем разбирать всю формулу bm25 полностью, но пройдемся по основным значениям.
f (qi, D) это частота слова qi в документе D, |D| является длиной документа (рассчитывается из количества в нем слов). аavgdl — это средняя длина документа в коллекции. k1 и b — это свободные коэффициенты, зачастую выбирают как k1 = 2.0 и b = 0.75. IDF (qi) представляет из себя обратную документную частоту слова qi. В настоящее время существует несколько объяснений IDF и небольших вариаций его формулы. В классическом варианте в bm 25 она определяется так:
где N обозначает суммарное количество документов в коллекции, а n (qi) — показывает числовое значение документов, которые содержат qi. Но в основном применяются более адаптированные варианты формулы, одна из них выглядит так:
Стоит обратить внимание, что в данной формуле IDF есть один недостаток. Для слов, которые входят более чем в половину документов из коллекции — значение IDF будет отрицательным. Простыми словами, это означает, что два почти одинаковых документа, в одном из которых есть определенное слово, а в другом нет — то второй документ может получить оценку больше чем первый. Другими словами, если слова часто встречаются в документе, то это отрицательно повлияет на окончательную оценку документа. Это является нежелательным эффектом при расчете вм25, поэтому во многих приложениях данная формула корректируется следующими способами:
- Игнорирование всех слагаемых в сумме (можно сказать, что это схоже с занесением в стоп-лист с целью проигнорировать все высокочастотные слова в тексте);
- Наложение на IDF функцию некую нижнюю границу \varepsilon: если значение IDF будет меньше, в таком случае она будет считаться равной \varepsilon;
- Использование другой формулы IDF, которая не принимает отрицательных значений.
BM25 °F — это модификация BM25, где документ анализируется как совокупность нескольких блоков (например, ссылочный текст, заголовки h1-h3, основная часть текста) длины которых независимо нормализуются, а каждому участку назначается своя степень значимости в итоговой функции ранжирования.
К сожалению, полный список критериев, а также конкретный вид формулы вм25 до сих пор коммерческая тайна поисковых систем. Что вполне естественно, ведь, владея точной информацией оптимизаторы могут воздействовать на алгоритм в своих интересах.



