
Вокруг нового обновления алгоритма Google много шумихи и неправильной информации. Что такое BERT, как он работает. И самое главное — как повлияет на работу SEO-специалистов?
Об этом расскажет Бритни Мюллер. Она занимается в Moz машинным обучением для обработки естественных языков. Далее с ее слов.
Введение
В конце октября Google начал вводить новый алгоритм. Он основан на методике предварительной тренировки систем обработки естественного языка BERT (Bidirectional Encoder Representations from Transformers), которую Google представил в прошлом году. Цель — лучше понимать сложные запросы и их контекст. Алгоритм анализирует не каждое слово последовательно, а все вместе
Это поможет Гуглу понимать значение длинных диалоговых запросов, запросов с предлогами и других естественных запросов, а также для расширенных сниппетов.
Пока BERT проходит тестирование в Америке и затрагивает только 10% всех запросов. Алгоритм будет дополнять RankBrain. В каких-то ситуациях будут применяться оба алгоритма, в каких-то — только тот, который дает более релевантный результат на вопрос пользователя.
Никто не отменяет главное правило: вам просто нужно писать хороший контент для вашей аудитории. Но я полагаю, многие из вас хотят разобраться, что к чему в новом алгоритме. Иначе вы бы не стали SEO-спецом :)
Если вам интересно узнать немного больше о BERT, чтобы, как минимум, лучше доносить информацию до своих клиентов, вам нужно прочитать эту статью до конца.
Не переоценивайте значимость обновления
Я смогла пообщаться с Эллисон Эттингер. Она занимается исследованиями в сфере обработки естественного языка. Она профессор университета в Чикаго.
Я сделала главный вывод из нашего разговора: не переоценивать значимость BERT. Сейчас ни одна система не в состоянии так понимать контекст, как это делает человек. Да, есть пресуппозиции в том же НЛП и машинном обучении, но давайте не рубить с плеча.
Предпосылки для введение BERT
Я хочу дать вам более широкий контекст, откуда появился BERT.
Обработка естественного языка
Компьютеры не могут понимать человеческий язык. Они могут хранить текст, который водит человек, но понять его — нет. И здесь нужно сказать про обработку естественного языка компьютером. В этой области ученые разрабатывают уникальные модели для решения конкретных задач, которые сводятся к пониманию машиной, что говорит человек.
Пара примеров: распознавание именованных объектов, классификация, анализ языковых конструкций, сопоставление вопросов и ответов.
Все эти задачи решались разработкой конкретного инструмента. Есть проблема — для нее ищут и разрабатывают решение. Похоже на кухню:
Подумайте об отдельных моделях распознавания языка. Это как принадлежности, которые есть у вас на кухне. Они выполняют определенную, специфическую задачу, но делают ее хорошо. В стаканы наливаем жидкость, ложками едим супы, вилками — вторые блюда.
Теперь рассмотрим универсальную кухонную утварь. Например, комбайн, который может справляться и с нарезкой овощей, и со взбиванием молока.
BERT — это такой комбайн, который может справляться с несколькими задачами, потому что он более универсален, чем остальные модели обработка языковых конструкций.
Поэтому велика вероятность, что Google внедрит BERT в общий алгоритм ранжирования.
Что будет происходить далее
Эллисон считает: “Какое-то время мы будем двигаться в одном направлении, создавать большие и лучшие варианты текущей модели BERT. В чем-то они будут действительно новы, но у них будут присутствовать все те же фундаментальные ограничения”.
Есть много разных версий BERT, и со временем их станет все больше. Пока не понятно, к чему это приведет.
Как происходит обучение алгоритма
Google взял много текстов из Википедии и арендовал вычислительные мощности. Они позволят обработать много текстовой информации. Неконтролируемая нейронная сеть будет изучать статьи из энциклопедии, чтобы лучше понять язык и контекст.
Алгоритм берет текст произвольной длины и парсит его в вектор. Вектор — это фиксированная строка чисел. Он помогает машине переводить естественный язык в компьютерный.
Вся работа происходит в n-мерном пространстве. Нам даже сложно представить его размерность. Похожие языковые конструкции разносятся по разным группам, которым они соответствуют по смыслу.
Для непосредственно обучения используется процесс, который называют маскированием. В предложении случайно слово скрывается маской:

Алгоритм смотрит на соседние слова и пытается понять, что за слово спрятано.
И так раз за разом.
Алгоритм может решить 11 типовых задач из области обработки и распознавания языка.
Что алгоритм не может делать
Подробная статья есть у Эллисон. Самый удивительный вывод — алгоритм плохо понимает отрицания и негативную эмоциональную окраску.
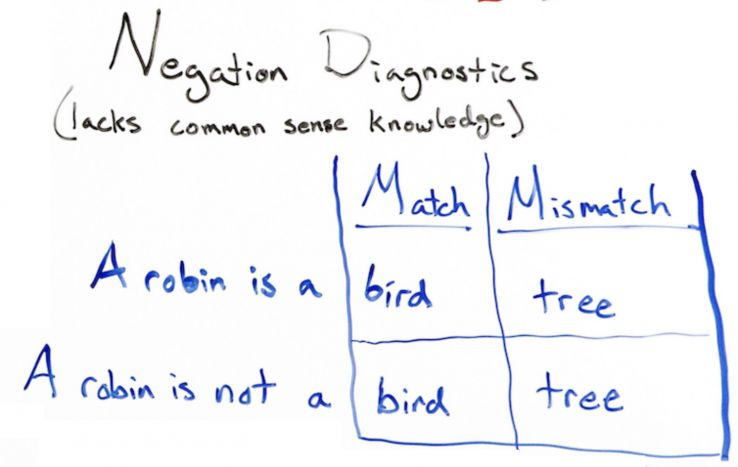
Например, на ввод отправляем вопрос: “Кем является Робин”. Алгоритм выдает ответ “птица”. Это верно. Но на вопрос “Чем Робин НЕ является?” алгоритм снова ответит “птица”. Это не верно.
Как оптимизировать под BERT? (Никак.)
Все верно. Никак. Единственное, что вы можете сделать — написать качественный текст и удовлетворить тот интент, с которым они на нее зайдут.
Если пишем про то, как варить пельмени, то нужно рассказать читателю именно про то, как, черт возьми, их варить. Не про виды начинок. Не про историю блюда. Не про разные составы теста. А про то:
- когда солить воду;
- когда кидать в нее пельмени;
- сколько минут варить.
Растущие возможности Google для понимания поисковых запросов
Об этом говорил Джеф Дин из Google. Он привел интересный пример. Предположим, вы задаетесь вопросом: “Можно ли принимать и совершать звонки, находясь в самолете?”

Блок текста, из которого Google пытается понять его смысл, очень непростой:
Режим “в самолете” — это настройка, доступная на многих смартфонах, портативных компьютерах и других устройствах, которая при активации приостанавливает передачу радиочастотного сигнала устройством, тем самым отключая Bluetooth, телефонию, WiFi. GPS-локация может или не может быть отключена, потому что она не передаёт никакие радиоволны.
Алгоритм смог дать ответ “Нет”, основываясь на всем этом сложном и длинном тексте. И это показательный пример.
Обучение BERT может оказать огромное влияние на нашу сферу. Поэтому важно понимать истоки алгоритма, и как он развивается.


