
С точки зрения SEO дубли страниц негативно влияют на ранжирование. Присутствие их на сайте может грозить фильтрами от поисковых систем и потерей позиций. В этой статье мы разберем, как находить внутренние страницы-дубли и как с ними бороться.
Дубли страниц что это
Это страницы с одинаковым наполнением (контент, товары, мета-теги). Они возникают из-за неправильной структуры домена или генерируются CMS автоматически.
К чему это приводит?
- Фильтры поисковых систем. Чем больше повторов, тем выше риск попасть под АГС или Панду.
- Низкая релевантность ресурса. Страницы с одинаковым контентом теряют позиции и трафик в выдаче.
- Долгая индексация. Чем больше страниц, тем больше времени требуется поисковым ботам для индексации.
Почему возникают дубли страниц
Выделяют 4 причины возникновения:
- Проблемы CMS. Автоматически создаются админкой при неправильной настройке генерации URL.
https://semantica.ru/
https://semantica.ru/index.php
- Ошибки в технических разделах. Характерны для Bitrix и Joomla, они возникают вследствие того, что панель управления создает отдельные страницы для функций сайта, таких как поиск, фильтрация или регистрация.
https://semantica.ru/rarticles.php
https://semantica.ru/rarticles.php?ajax=Y
- Человеческий фактор. Невнимательность при размещении контента или добавлении карточек в интернет-магазине может привести к возникновению повторов.
- Технические ошибки. Некорректная настройка CMS и генерации ссылок может приводить к сбою и образованию цикличности.
https://semantica.ru/tools/tools/tools/
Какие виды дублей существуют
Их можно разделить на две группы — полные и частичные.
Полные:
- Версия страницы http/https, c www и без, index.php/html, home.php/html, бесконечное число слэшей, доступность страницы в разных регистрах URL или с несуществующими в нем символами.
- UTM-метками и GET-параметрами (?, *).
- Одинаковое наполнение на страницах с разными URL-адресами.
- Неправильно настроенная страница 404.
Частичные:
- Пагинация и фильтры.
https://semantica.ru/catalog/
https://semantica.ru/catalog/?page=2
- Отзывы. При открытии вкладки на карточке товара внешний вид сохраняется, а к URL добавляется GET-параметр.
- Страницы для скачивания.
https://semantica.ru/stranica/
https://semantica.ru/stranica/print/
Дублирующийся контент
Такие дубли возникают при одинаковом описании товара на листинге в каталоге и в карточке, а также при размещении одинаковой информации, которая будет доступна по разным URL-адресам.
Еще одна причина появления — это одинаковый текст на основной странице и всех разделах сайта. Лучше размещать такую информацию кратко или ссылкой на страницу с полным описанием.
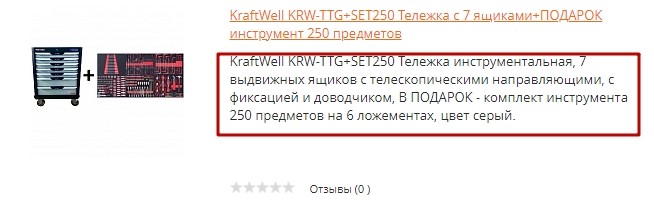

Также не следует копировать информацию с других источников, даже если это описание товара или услуги, которые вы тоже продаете, так как это тоже приводит к появлению дублей, но не только на ресурсе, а в рамках всего интернета.
URL с параметрами
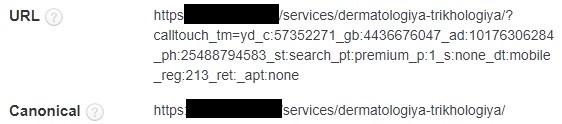
Сюда относятся страницы пагинации, фильтры и UTM-метки, например, from, utm_content, utm_term. GET-параметры формируются после основного адреса и начинаются со знака вопроса.
Такие метки как, например, /?page=1 и /?sort=, автоматически генерируются CMS при переходе по страницам пагинации или при применении фильтров в каталоге.
UTM-метки добавляются на сайте при подключении рекламной кампании или сервисов для аналитики и отслеживания трафика.


Дубли с параметрами необходимо отслеживать и закрывать от индексации. Для этого используется директива Disallow или Clean-param в robots.txt. Также для устранения подойдет тег canonical, где канонической будет страница без GET-параметра.
Также для страниц пагинации можно прописать уникальные мета-теги.
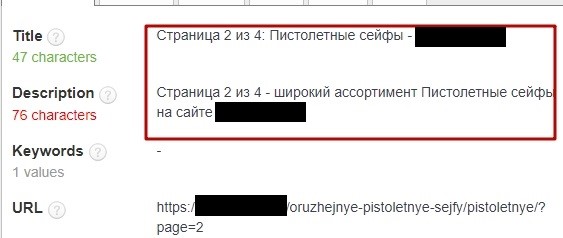
Дубли карточек товаров
Это один и тот же товар из каталога, доступный по разным URL-адресам.
Эти страницы дублируют друг друга, что негативно сказывается на их ранжировании. Для решения этой проблемы необходимо настроить 301 редирект со всех дублирующих страниц на основную.
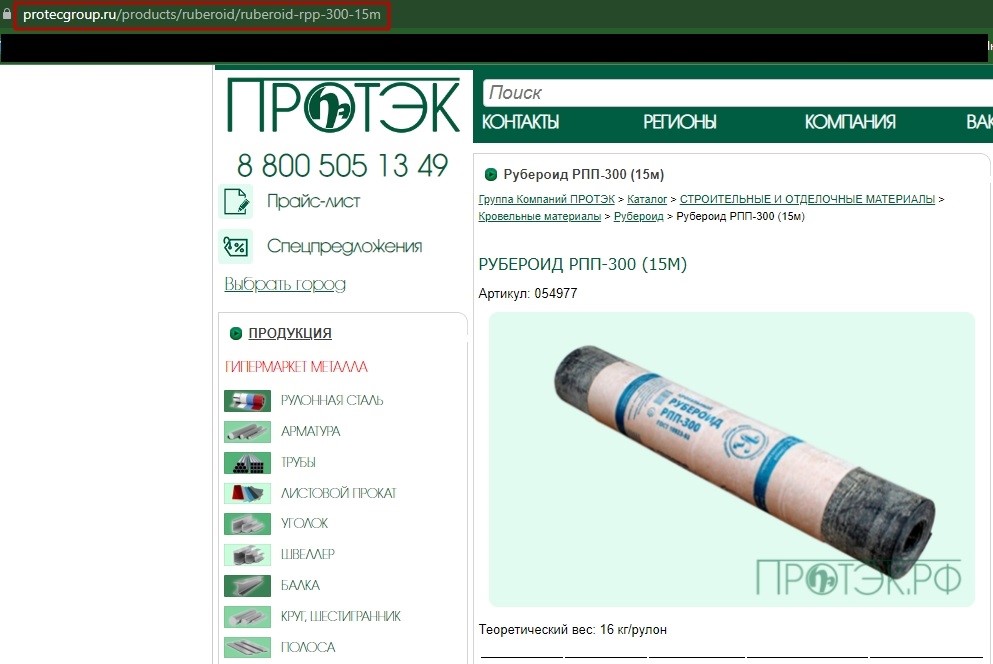
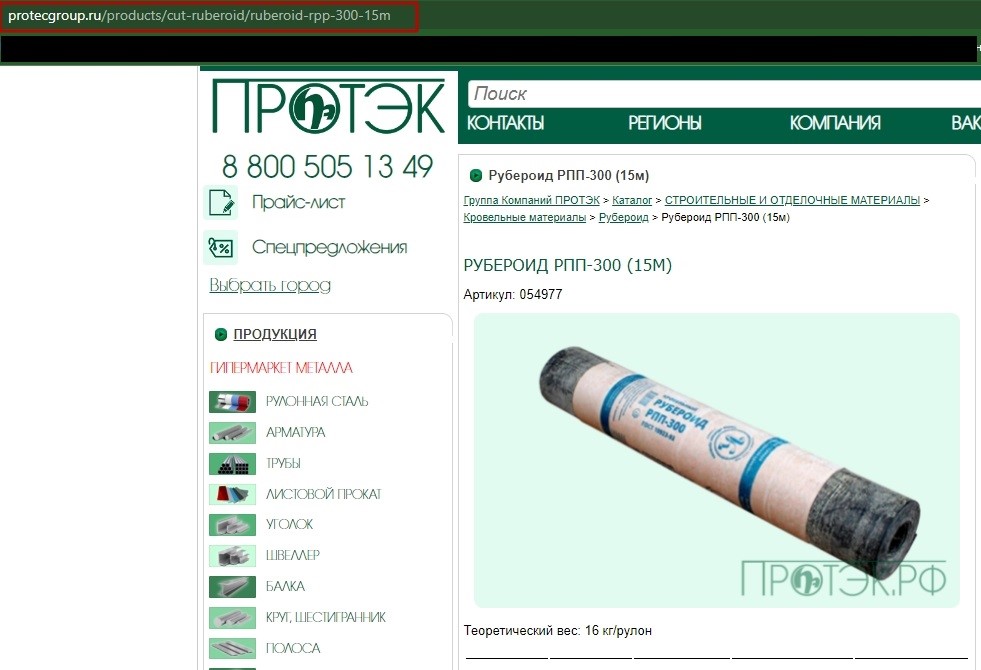
Также дублями могут считаться карточки, имеющие незначительные отличия, например, некоторые характеристики. Поисковики могут выбрать одну из них и посчитать ее основной, а остальные признать неоригинальными. Чтобы этого избежать, не следует создавать страницы для каждого типа товара (разный цвет или размер), а объединить их в один с возможностью выбора необходимой характеристики.
Региональные версии сайта
При использовании подпапок для поддоменов, контент с основного домена полностью дублируется для регионов. Чтобы избежать такого дублирования, следует создавать поддомены и наполнять их оригинальным контентом.
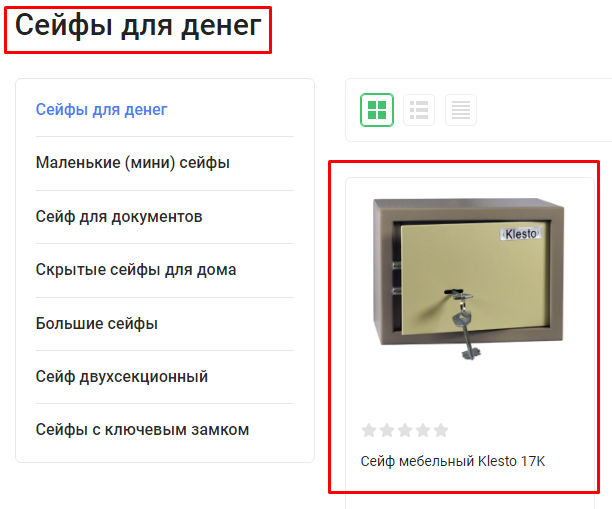
Несколько категорий для одного товара
Часто в интернет-магазинах разные позиции добавляются сразу в несколько разделов, например, https://semantica.ru/catalog/obuv/tufli/model1234 и https://semantica.ru/catalog/obuv/tufli-letnie/model1234.
Чтобы такого не происходило, необходимо настроить корректную генерацию URL. Правильно будет так: все товары, которые добавлены в разные категории, имеют один адрес и открываются по нему.

Технические дубли
Наиболее распространенные из всех. Возникают из-за автогенерации самой CMS.
К ним относятся:
- Дубли главного зеркала
https://semantica.ru/
https://www.semantica.ru/
или
https://semantica.ru/
http://semantica.ru/
- Cо слешем и без него в конце URL.
https://semantica.ru/
https://semantica.ru
- Index.php, home.php, index.html, home.html.
https://semantica.ru/index.php
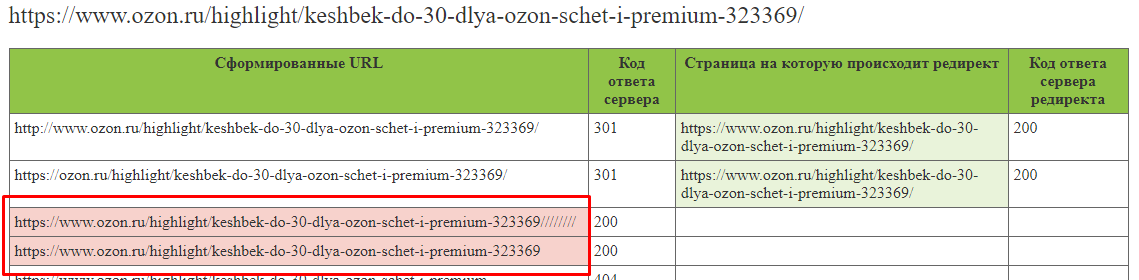
- C любым количеством слэшей между частями URL и рандомными символами.
https://semantica.ru/////////
https://semantica.ru/catalog/aksfhskdf
Для решения таких проблем подойдет настройка 301 редиректа на основную страницу.
Поиск дублей страниц
Чтобы устранить проблему, ее сначала необходимо найти. Для этого можно воспользоваться следующими методами.
Поиск "вручную"
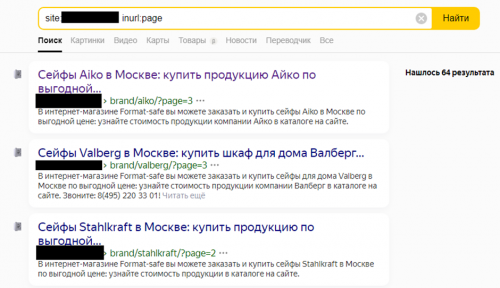
Этот способ подходит для поиска пагинации и фильтров. Зайдите в каталог и, воспользовавшись функцией сортировки или поиска по страницам, посмотрите добившиеся к URL параметры.
Также вы можете воспользоваться поисковой строкой и найти дублирующиеся страницы через него. Для этого необходимо ввести site:(доменное имя) inurl:(часть URL).
Яндекс.Вебмастер
Если сайт подключен к этой системе аналитики, вы можете отслеживать появляющиеся на нем дубли через нее.
Чтобы проверить, есть ли они, заходим в раздел “Индексирование” → “Страницы в поиске”.
Далее выбираем “Исключенные” → “Исключенные страницы” и сортируем все страницы по статусу “Дубль”.
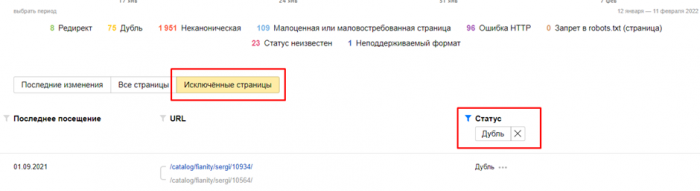

Сюда будут вынесены все повторы, встречающиеся на сайте — карточек товаров, страницы пагинации, GET-параметры и UTM-метки, страницы с дублирующимся контентом.
Для удобства Вебмастер указывает, какая страница признана поисковой системой основной, а на какой странице контент дублируется.
ГЕТ-параметры выделяются сервисом в критичные ошибки и выводятся на главной странице.

Google Search Console
Чтобы проверить наличие дублей через GSC заходим в раздел “Покрытие” → ”Полный отчет”.
Далее выбиваем “Исключено”.
Если они есть, увидеть их можно в категории “Страница является копией. Канонический вариант не выбран пользователем”.
Минус проверки через GSC в том, что нет возможности увидеть основную страницу.

Apollon
Сервис подойдет для поиска ошибок, генерируемых CMS. Для проверки нужно в поле ввода URL добавить основной урл страницы и начать проверку.
Красным будут отмечены найденные на сайте проблемы.
Как убрать дубли страниц
После того, как они были найдены, нужно выбрать способ, как с ними бороться. Дальше расскажем о нескольких из них.
301 редирект
Самый надежный способ устранения. Он подойдет для устранения дублей CMS или карточек товара, но не подойдет для страниц с GET-параметрами и UTM-метками.
- Чтобы его сделать, действуем следующим образом — выбираем проблемную страницу, например, home.php и прописываем следующее правило в файле .htaccess:
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9} /home.php HTTP/
RewriteRule ^home.php$ http://VASHSITE/ [R=301,L]
- С неглавного зеркала, используйте такое правило:
RewriteCond %{HTTP_HOST} ^www\.(.*)$
RewriteRule^(.*)$ http://site.ru/ [L,R=301]
- С дублирующих страниц прописываем правило:
Redirect 301 /was.php https://semantica.ru/new.php
Адрес страницы перенаправления необходимо указывать полностью.
Тег canonical
Такой способ подойдет для пагинации, фильтров и меток. Чтобы настроить каноникал, прописываем для дубликатов правило:
<link rel= “canonical” href= "https://semantica.ru/osnovnaya-stranica.html”>.
Эти действия можно проделать вручную для каждой страницы, но чем их больше, тем это трудозатратней. Чтобы упростить и ускорить этот процесс, можно воспользоваться одним из следующих плагинов, например: SEO Link Canonical, Yoast SEO (для WordPress), Aimy Canonical PRO (для Joomla).
Disallow в robots.txt
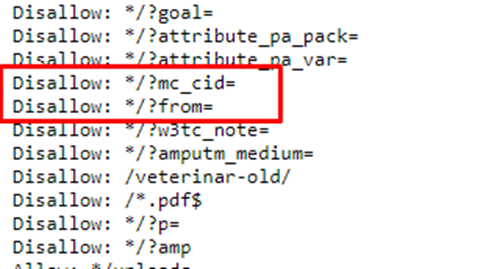
В файле роботс содержится информация о том, как правильно индексировать сайт. Предназначается она поисковым ботам. Здесь вы можете указать, на какие куда ботам заходить не нужно. Такой способ подойдет для некоторых GET-параметров, например, /?from=, /?calltouch_tm=, /?mc_cid=.
Чтобы запретить индексацию дублей через robots.txt, необходимо прописать в нем запрещающую директиву Disallow c указанием URL или его часть.
Clean-param
Директива для Яндекс, используемая для закрытия от индексации страниц рекламных кампаний. Без настройки Clean-param такие страницы будут массово проверяться ботами и признаваться дублями.
Чтобы настроить Clean-param в файле robots.txt в User-agent: Yandex, прописываем, например:
Clean-param: utm_source=yandex&utm_medium=cpc&utm_campaign=audit
Это правило закрывает все страницы с параметром utm_source=yandex&utm_medium=cpc&utm_campaign=audit.
Заключение
Дубли страниц, попавшие в поисковую выдачу, негативно влияют на ранжирование сайта. Они могут нанести урон не только в рамках конкретного URL, но и всего домена. Поэтому стоит отслеживать и вовремя устранять такие страницы, ведь способов их обнаружения и устранения достаточно много.




