

Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
Представьте, что вы отправились за сокровищами на остров. У вас есть карта. Там указан маршрут: “Подойти к большому пню. От него сделать 10 шагов на восток, затем дойти до обрыва. Повернуть вправо, найти пещеру”.
Это — указания. Следуя им, вы идете по маршруту и находите клад. Примерно также работает и поисковой бот, когда начинает индексировать сайт или страницу. Он находит файл robots.txt. В нем считывает, какие страницы нужно проиндексировать, а какие — нет. И, следуя этим командам, он обходит портал и добавляет его страницы в индекс.
Для чего нужен robots.txt
Роботы поисковых систем начинают ходить по сайтам и индексировать страницы после того, как сайт загружен на хостинг и прописаны dns. Они делают свою работу вне зависимости от того, есть у вас какие-то технические файлы или нет. Роботс указывает поисковикам, что при обходе веб-сайта нужно учитывать параметры, которые в нем находится.
Отсутствие файла robots.txt может привести к проблемам со скоростью обхода сайта и присутствия мусора в индексе. Некорректная настройка файла чревата исключением из индекса важных частей ресурса и присутствием в выдаче ненужных страниц.
Все это, как результат, ведет к проблемам с продвижением.
Рассмотрим подробнее, какие инструкции содержатся в этом файле, как они влияют на поведение бота у вас на сайте.
Как сделать robots.txt
Для начала проверьте, есть ли у вас этот файл.
Введите в адресной строке браузера адрес сайта и через слэш имя файла, например, https://www.xxxxx.ru/robots.txt
Если файл присутствует, то на экране появится список его параметров.
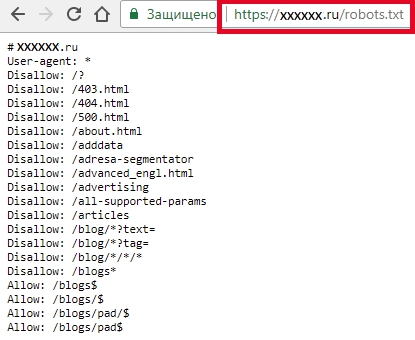
Если файла нет:
- Файл создается в обычном текстом редакторе типо блокнота или Notepad++.
- Нужно задать имя robots, расширение .txt. Внести данные с учетом принятых стандартов оформления.
- Можно проверить на предмет ошибок с помощью сервисов типа вебмастера Яндекса.Там нужно выбрать пункт «Анализ robots.txt» в разделе «Инструменты» и следовать подсказкам.
- Когда файл готов, залейте его в корневой каталог сайта.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые — только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Сейчас есть две ключевых поисковых системы: Яндекс и Google, соответственно, важно при составлении сайта учитывать требования обеих.
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки.

Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.

Такой вариант, наоборот, означает полный запрет индексации для всех.

Запрет на просмотр всего содержимого определенной папки-каталога

Для блокировки одного файла нужно указать его абсолютный путь

Директивы Sitemap, Host
В файл, как правило, добавляют ссылку на «Sitemap» (карту сайта), чтобы облегчить боту ее поиск.
Для Яндекса в директиве Host принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.

Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.

Директива Crawl-delay
С помощью нее можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.

Ошибки robots.txt
- Файл не находится в корневом каталоге. Глубже робот его искать не будет и не учтет.
- Буквы в названии должны быть маленькие латинские.
Ошибка в названии, иногда упускают букву S на конце и пишут robot. - Нельзя использовать кириллические символы в файле robots.txt. Если нужно указать домен на русском языке, используйте формат в специальной кодировке Punycode.
- Это метод преобразования доменных имен в последовательность ASCII-символов. Для этого можно воспользоваться специальными конвертерами.
Выглядит такая кодировка следующим образом:
сайт.рф = xn--80aswg.xn--p1ai
Дополнительную информацию, что закрывать в robots txt и по настройкам в соответствии с требованиями поисковиков Гугл и Яндекс можно найти в справочных документах. Для различных cms также могут быть свои особенности, это следует учесть.


