Машинное обучение в большей степени используется для автоматизации сложных задач. То есть, само по себе оно ничего не решает. И более того, термин появился еще в 50-х годах прошлого века, но для реализации обучения должны быть технологии и задачи (или цели), именно они помогают формировать наше будущее, подгоняя друг друга.
Сейчас поиск использует машинное обучение, но это никак не связано с человечностью. Как только возникнут соответствующие задачи, появятся нужные технологии, тогда мы уже будем оперировать персональным помощником (вместо поисковика), использующим искусственный интеллект.

Машинный поиск – это все же немного другое, не попытка воссоздать человеческий способ мышления. Скорее, это способ найти в нем хоть какую-то логику. Чтобы нейронная сеть могла угадывать, что имел в виду человек, ей нужна достаточно большая достоверная выборка для обучения. Если такой выборки нет, то предсказание получится не очень качественным, так как будет основываться на ложных предпосылках.
Говоря простым языком, все, что не укладывается в логику, представленную большим объемом данных, будет оставаться за гранью понимания поисковых систем.
Другой вопрос, что из сотен тысяч слов средний человек использует всего 2–3 тысячи. Так что даже если логика большинства еще не просчитана, ждать этого осталось недолго.
Возвращаясь к вашему вопросу. Человечнее поиск не станет, потому что это не является его целью. Но с накоплением данных он станет лучше понимать, что пытается найти каждый конкретный человек. И чтобы это было действительно так, стоит ждать больших попыток отследить действия этого конкретного человека.
С одной стороны, удобно. С другой, параноикам выживать будет сложнее. С третьей, наверно, не очень хорошо, что предложение информации будет сужаться персональным опытом, а для получения новой неизученной информации придется выходить из зоны комфорта, не заниматься самостоятельными исследованиями, а в прямом смысле этого слова заимствовать чужой опыт. Первые попытки так с нами поступить мы наиболее ярко видим на примере ленты фейсбука. И от этого немного не по себе.

Трудно комментировать машинное обучение, потому что сейчас все проекты направлены на его использование. Однако, тот факт, что премьер-министр Дмитрий Медведев выкладывает каждое третье фото в своем аккаунте Инстаграм с применением фильтров от Prizma, говорит о том, что тренд долгий и будет развиваться. Те же чат-боты становятся все больше похожи на людей и дают возможность бизнесу экономить на заработных платах (операционных издержках). Автоматизация любого бизнеса сейчас во главе угла и неважно, поисковые ли это системы или обычная компания, которая продает пластиковые окна.
Что касается поисковых запросов, то уже сейчас все решает аналитика и работа со спросом во всех нишах. В течение двух лет сами по себе запросы будут представлять ценность потенциального клиента, поисковые системы будут все больше шифровать данные на фоне роста ставок в контекстной рекламе. Уже сейчас низкочастотные запросы недоступны для аналитики в широком смысле слова. Тренд будет всё больше формироваться в поиске, в Яндекс в первую очередь.

Мне очень понравился последний релиз про Палех. «Мы придумали Палех, чтобы улучшить результат на малых данных, но он на малых данных работает плохо, поэтому ему нужно собрать побольше статистики».
Машинное обучение в поисковиках – это в первую очередь принятие решения о ценности того или иного фактора на основании статистики. На конференции «Как работает Поиск» Яндекс рассказывал о том, как они добавили 1500-й фактор в МатриксНет. Точно так же, как при запуске МатриксНета: специалист генерирует гипотезу, проверяет ее на контрольной выборке, и дальше человек принимает решение жить или нет новому фактору.
Так что пока это не машинное обучение, а просто более хитрый скрипт, не более того. И объявить крестовый поход против «создания множества страниц под низкочастотники» должен не скрипт машинного обучения, а конкретный сотрудник поисковой машины, имя и фамилию которого всегда можно будет узнать. Так или иначе, пока в топе поисковиков попадаются мусорные дорвеи, ни о каких принципиальных изменениях в правилах игры говорить нельзя.

Думаю, скоро поиск научится понимать смысл документа без прямых вхождений ключевых слов. Яндекс уже сделал первый шаг к такому пониманию, запустив Палех, который пока что работает только с заголовками.
Вероятно, одним из следующих шагов будет анализ всего текста страницы по таким же принципам. Если так, то некоторые моменты в работе оптимизаторов придется пересмотреть. Вместо использования привычной кластеризации по топам нужно будет учиться группировать запросы по смысловому интенту, придется искать новые подходы к текстовой оптимизации. Но пока об этом говорить еще рано.

Сделает ли машинное обучение поиск человечнее?
В этой, на первый взгляд, парадоксальной фразе скрыта основная задача и нового алгоритма «Палех» от Яндекса, и поискового сигнала RankBrain от Google, и прочих недавних нововведений. Поисковые системы непрерывно стремятся к тому, чтобы понимать запрос пользователя не как «бездушная машина», а как «добрый приятель», Человек с большой буквы.
Поисковые системы:
- Помнят ваши предпочтения (долгосрочная персонализация).
- Понимают ваше настроение (сиюминутная персонализация).
- А теперь, после запуска «Палеха» и RankBrain, ещё и читают между строк, а не просто ищут документы с вхождением слова из запроса.
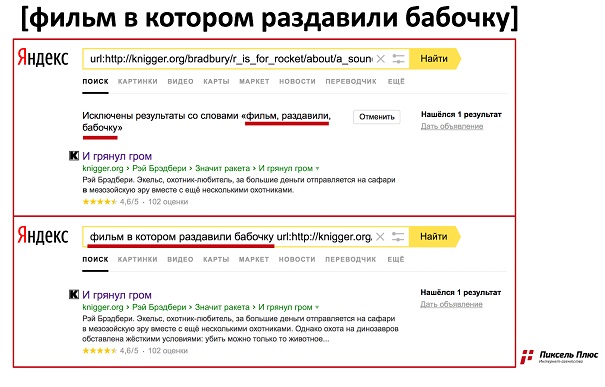
Сейчас, при стечении ряда обстоятельств, на первых местах в выдаче могут оказаться сайты без слов из поискового запроса (см. пример).