

Большая техническая статья о том, как анализировать поведение поисковых ботов через информацию из логов сервера. Вам потребуется владение базовыми функциями электронных таблиц и понимание информации, которая фиксируется в логах. А получите вы гораздо больше инсайтов, чем при использовании стандартных программ-анализаторов для SEO.
Анализ логов должен быть частью рабочего процесса любого оптимизатора. Если вы не анализируете файлы журналов, вы упускаете много возможностей раскрутить свой сайт. Часть информации не способен дать ни один анализатор сайта.
Из статьи вы узнаете, какую информацию можно вытащить из логов, чтобы использовать все возможности продвижения.
- Что такое логи сервера и какая в них есть информация
- Как открыть и посмотреть логи сервера
- Как разобраться в Log-файле
- Как быстро выяснить лимит робота на индексирование страниц
- Анализируем поведение поисковых роботов
- Ищем проблемы со сканированием
- Ищем проблемы на страницах
- Логи сервера — совсем не страшно!
Что такое логи сервера и какая в них есть информация
Файлы логов — это подробная информация о запросах, которые поступают и обрабатываются на сервере сайта. Каждый раз, когда бот отправляет запрос, данные попадают в специальный журнал: время, дата, IP-адрес, пользовательский агент и т. д.
Эти данные позволяют специалисту узнать, что делает Googlebot и другие роботы на сайте. В отличие от обычного сканирования, например, которое делаем с помощью Screaming Frog, в журнале — реальные данные о том, как робот видит ваш сайт.
Наличие такой точной информации поможет точнее понять, на что в первую очередь тратить бюджет, как вы можете улучшить обход сайта и его ранжирование. Бонус: вам для анализа не потребуется ничего устанавливать и покупать.
В руководстве я расскажу про инструмент для анализа логов Log File Analyzer, в котором есть функции для работы с большими данными.
Как открыть и посмотреть логи сервера
Изменить расширение с .log на .csv
Это первое, что необходимо сделать. Далее откроем файл в любой электронной табличке.
Как открыть несколько раздельных логов
Все происходящее может фиксироваться либо в одном большом логе, либо разделяться на несколько более мелких файлов. Это зависит от конфигурации сервера вашего сайта. Так, некоторые серверы для соблюдения сбалансированной нагрузки распределяют и трафик. Поэтому логи тоже будут разделены на несколько частей.
Но не пугайтесь: их можно легко объединить в один файл. Вот несколько способов, как это сделать.
В командной строке Windows зажмите Shift и щелкните правой кнопкой по каталогу, в котором находится нужный лог, выберите из списка этот пункт:
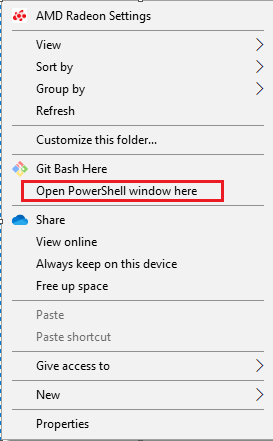
Затем выполните следующую команду: copy *.log mylogfiles.csv .
Теперь в файле лога mylogfiles будут все данные из журналов событий.
Другой вариант— для Mac. Используйте cd command, чтобы перейти в директорию в логами: cd Documents/MyLogFiles/ .
Далее выполните команду cat *.log > mylogfiles.csv .
Второй способ — использовать бесплатный инструмент Log File Merge, скомбинировать все файлы логов и потом конвертировать в формат .csv.
Третий вариант — инструмент от Screaming Frog — Log File Analyzer. В нем очень просто с технологией d&d соединять разрозненные логи:
Разделение строк
Есть вероятность, что строковые данные окажутся слиты друг с другом. Для удобства их нужно разделить по нескольким столбцам.
Есть специальная функция в Excel. Раздел “Данные” > “Текст в столбец”, в качестве разделителя укажите пробел.
После разделения строк, можно отсортировать записи по времени или дате, а также отделить их друг от друга символом “:”. Получится как на скриншоте ниже:
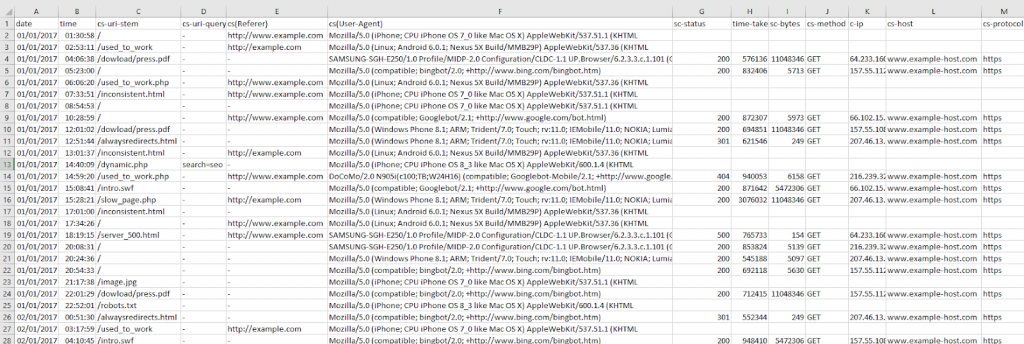
Как я уже говорил ранее, не старайтесь искать какой-то эталонный шаблон. Вам нужен доступ к базовым полям — время, дата, URL-адрес и т. д.
Как разобраться в Log-файле
После подготовки и приведения файлов в читабельный вид, мы можем погрузиться в данные и начать с ними работать. Есть несколько форматов информации, которые отражаются в логах:
- IP сервера;
- дата и время;
- тип метода в запросе (get или post);
- запрашиваемый URL;
- статус кода HTTP;
- user-agent.
Более подробную информацию можно найти, если вы заинтересованы в деталях:
- WC3;
- Apache и NGINX;
- HA Proxy;
- JSON.
Как быстро выяснить лимит робота на индексирование страниц
В качестве краткого обзора: бюджет на обход — это количество страниц, которое поисковик сканирует при каждом посещении вашего сайта. На это влияет множество данных: равенство ссылок, качество и авторитетность домена, скорость работы сайта и т. д.
Мы сможем узнать, какой бюджет сканирования у вашего сайта, где возникают проблемы с обходом страниц, которые этот лимит снижают.
Идеальный вариант — предоставить сканерам максимально удобный вариант обхода страниц. То есть, не нужно тратить бюджет на обход незначимых страниц. А приоритетные страницы не должны страдать из-за того, что на вашем сайте много мусора.
Таким образом, мы стараемся максимально сохранять бюджет на сканирование, потому что это обеспечивает лучшее присутствие в органической выдаче.
Поиск сканируемых страниц через user agent
Если увидите, какие URL бот просматривает чаще остальных, узнаете, в каких местах велики риски потратить бюджет на сканирование.
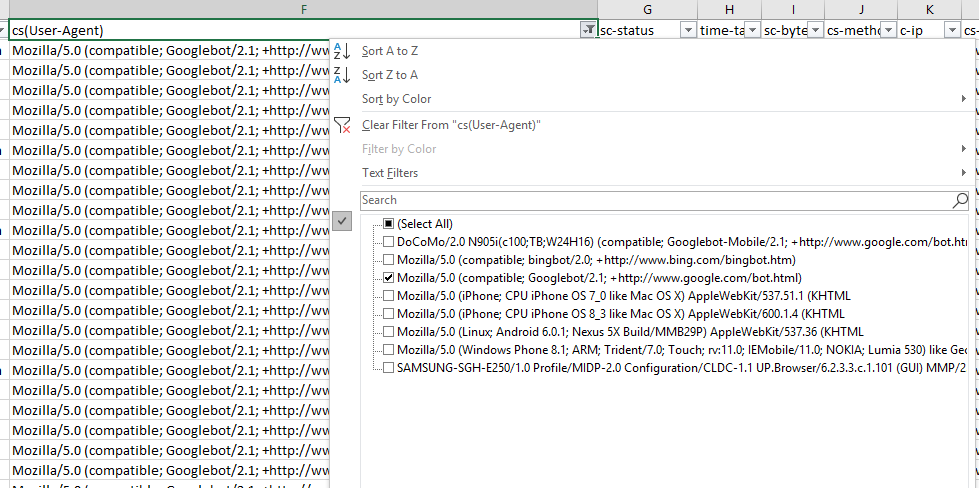
Если вам интересно посмотреть на поведение отдельного UA, просто отфильтруйте соответствующий столбец в логе. Для примера ниже: формат файла WC3, я фильтрую поле cs(User-Agent):
Далее узнаем, сколько раз Googlebot посещал каждую страницу, отфильтруем по полю URI — идентификатору ресурса.
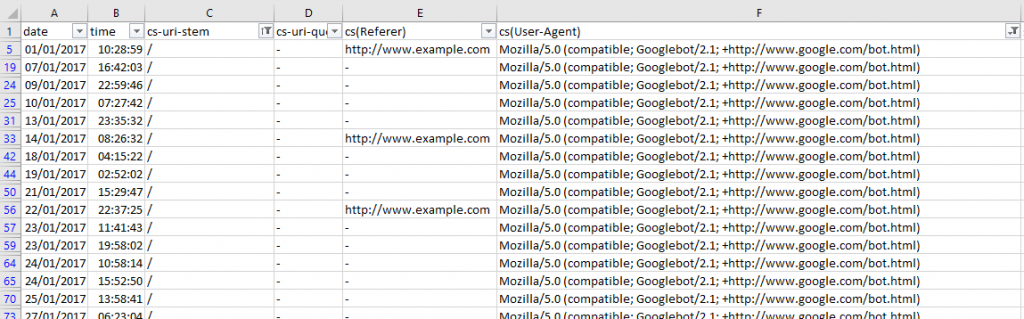
Быстрый способ узнать, есть ли какие-то проблемы user-agent — посмотреть на столбец cs-uri-stem
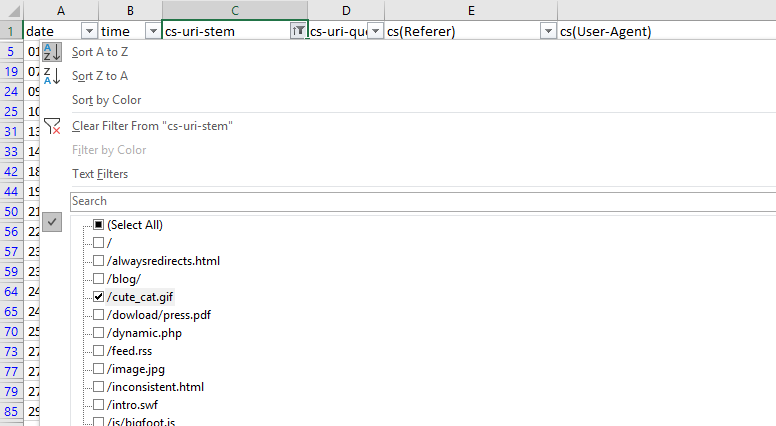
Отсюда видим, какие URL включая медиафайлы, подверглись обходу, и с ними возникли проблемы (например, URL с динамически подставляемым параметром, который не нужно индексировать).
Вы также можете выполнить более широкий анализ при помощи сводных таблиц. Чтобы узнать, сколько сканирований определенного URL было с указанным user agent, выделите всю таблицу и используйте следующие параметры:
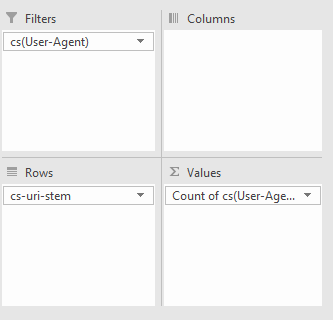
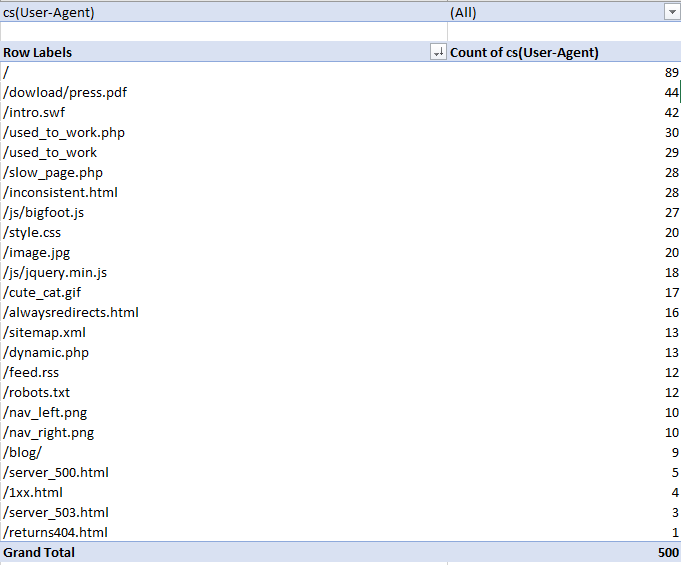
Все, что мы делаем — фильтрация по полю user agent, а затем подсчет, сколько раз встречается то или иное вхождение. Для своего примера у меня получилось:
Затем для фильтрации выбираем из полей User agent те, которые содержат Googlebot.
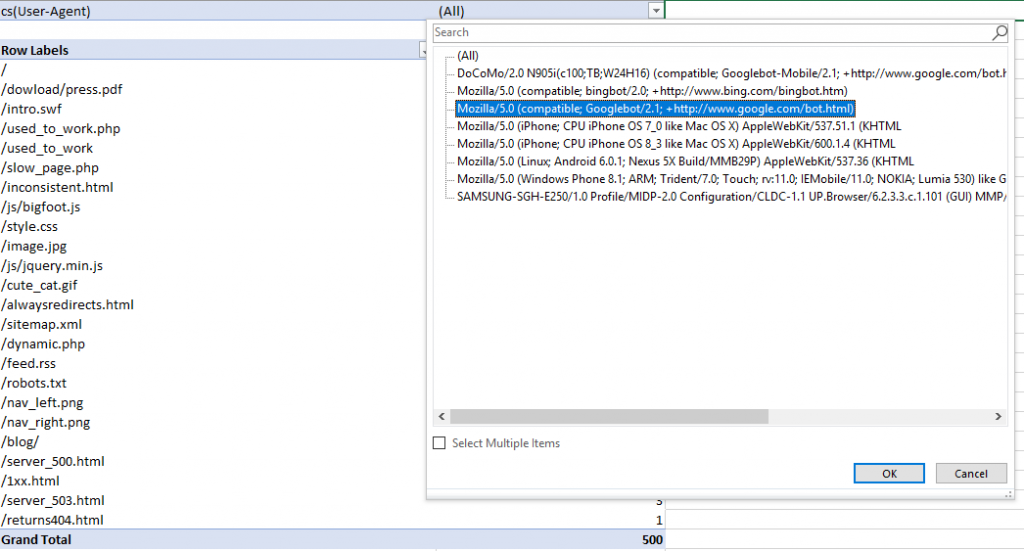
Понимание, как разные роботы сканируют страницы, даст и представление, где расходуется бюджет. А значит, даст пищу для размышлений: что можно улучшить.
Поиск некачественных адресов, которые тратят бюджет на сканирование
Не тратьте возможности Гуглбота на обход страниц с низкой ценностью. Я имею в виду случаи, когда робот обходит параметрические урлы, незначимые страницы категорий, которые являются промежуточными в цепочке навигации, или отражают в себе ID сессии.
Вернитесь к логу и отфильтруйте URL-адреса, которые содержат “?”. Если работаете в Excel, добавьте символ “~” как на примере ниже. Это символ экранирования.
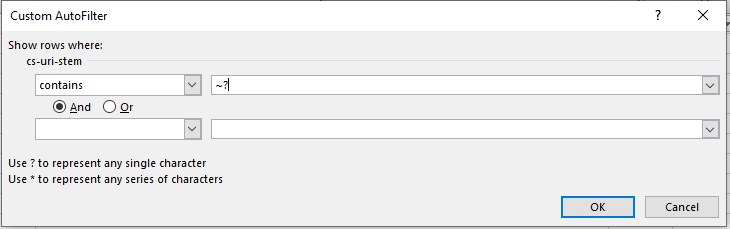
В противном случае вы выберите те урлы, в которых есть один произвольный символ. То есть, в выборку попадут все адреса из таблицы.
Поиск дублирующихся адресов
Дубли страниц — бесполезная трата бюджетов сканирования. Но найти их не всегда так просто, особенно когда адреса могут незначительно друг от друга отличаться.
В конечном итоге, лучший способ найти повторяющиеся адреса — отсортировать список по алфавиту и вручную его просмотреть. Один из способов найти несколько версий одного и того же адреса — использовать функцию SUBSTITUTE и удалить все слэши:
=SUBSTITUTE(C2, “/”, “”)
В моем случае целевая ячейка — С2, поскольку данные находятся в третьем столбце. Потом я использовал условное форматирование, чтобы выделить дубли:
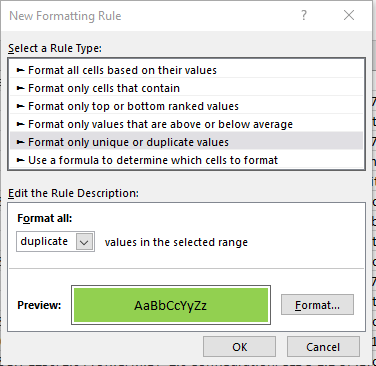
Однако все равно придется вручную отсматривать все записи. Чудес пока нет.
¯\_(ツ)_/¯
Частота обхода подкаталогов
Выясните, какие подкаталоги робот просматривает чаще всего. Это еще одна возможность выявить, куда тратится лимит на обходы. Но имейте в виду: даже если раз в год на блог бабушка ставит ссылку, ссылочный профиль всегда должен быть в идеальном состоянии.
Для поиска частоты обхода поддиректорий также придется много работать руками. Но поможет следующая формула:
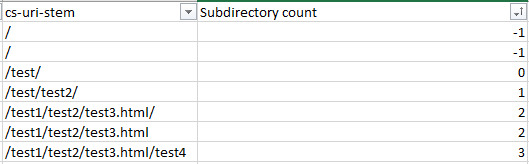
=IF(RIGHT(C2,1)="/",SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"/","")))/LEN("/")+SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"=","")))/LEN("=")-2, SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"/","")))/LEN("/")+SUM(LEN(C2)-LEN(SUBSTITUTE(C2,"=","")))/LEN("=")-1)
Эта формула проверяет наличие косой черты. Она вычисляет их количество и вычитает 2 или 1 из этого числа. То, останется — это количество поддиректорий.
Замените C2 на первое отделение в адресе, затем распространите формулу по всему списку.
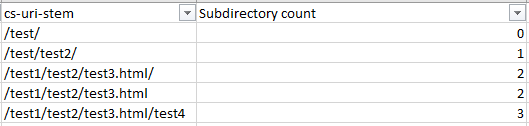
Убедитесь, что заменили значения во всех ячейках столбца. Потом их можно отсортировать по количеству директорий и получить страницы, наиболее удаленные, следовательно, затратные с точки зрения ресурсов на обход.
Частота обхода в зависимости от типа контента
Здесь будем проверять, какой тип контента каких бюджетов требует. С точки зрения технический оптимизации это — must have. Например, можем найти слишком частое сканирование ненужных файлов CSS и JS с низким приоритетом вместо обхода картинок, которым вы уделяете больше внимания.
Все это мы также можем сделать через Excel.
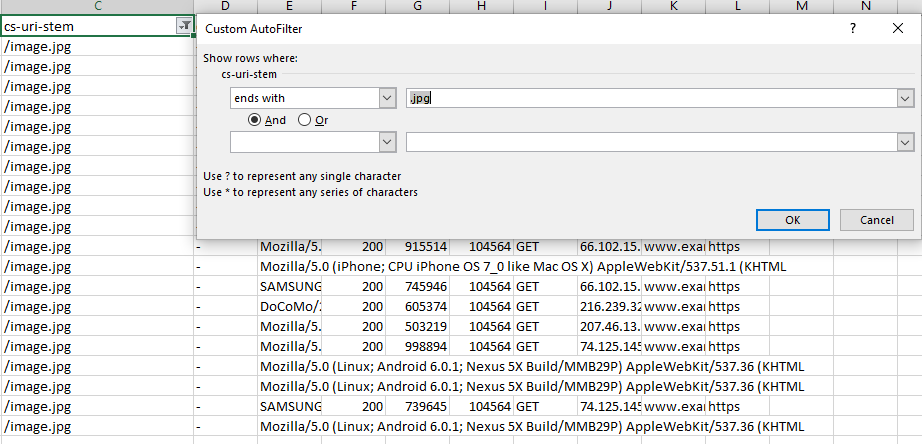
Анализируем поведение поисковых роботов
Здесь будем разбираться, как себя ведут на сайте различные поисковые роботы. Это нужно, чтобы лучше понимать принципы SEO и ранжирования, а кроме этого — эффективна ли структура сайта.
Самые часто обходимые URL
Идея такая же, как сортировка по значению поля user-agent, но этот способ быстрее.
В Excel выберите ячейку в сводной таблице > Вставить > Сводная таблица. Убедитесь, что выделенный фрагмент содержит необходимые столбцы — URL и URI и нажмите “ОК”.
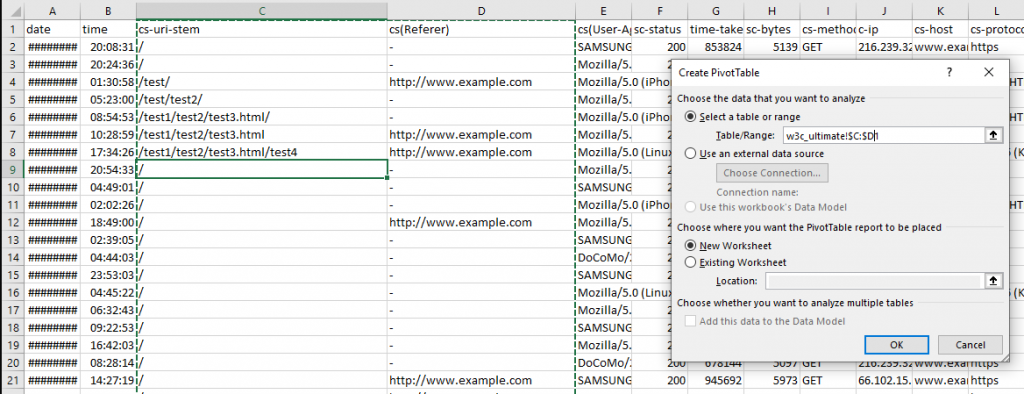
Установите показы URL или URI и сведите данные как user-agent.
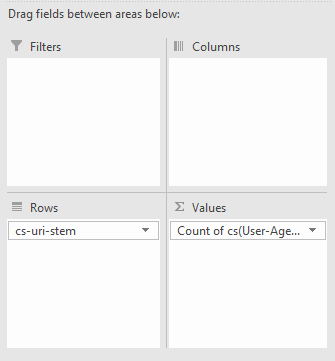
Далее правой кнопкой по столбцу user-agent и отсортируйте по убыванию количества обходов.
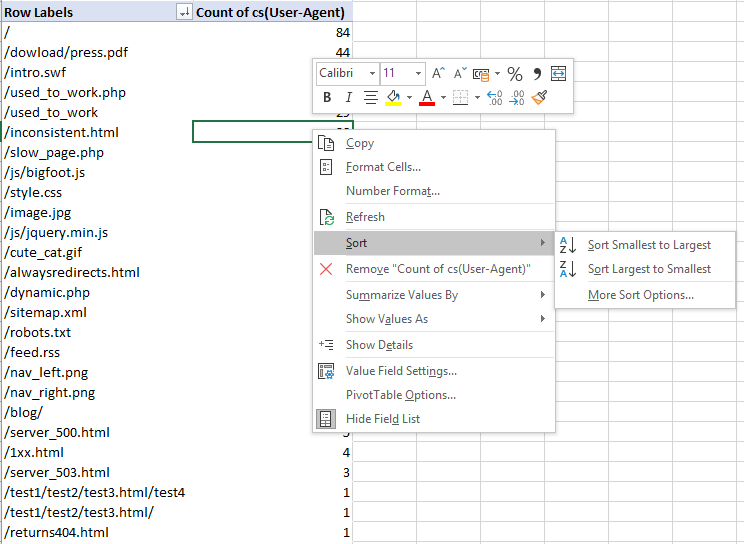
Мы получили таблицу, из которой легко видно проблемные места.

Задайте себе вопросы:
- все ли страницы здесь есть из тех, которые должны быть просканированы?
- с какой частотой?
Частое сканирование не обязательно означает лучшие результаты. Это может указывать, чему поисковики отдают больший приоритет.
Дневная, недельная и месячная частотность сканирования
Здесь мы узнаем, видимость каких страниц в ПС нужно улучшить. Полезный инструмент для отслеживания, например, апдейтов поисковиков. Если что-то изменится, вы сразу об этом узнаете.
Убедитесь, что столбец с датой обхода имеет верный формат данных, и упорядочьте его. Если вы просто хотите посмотреть данные за неделю, выберите соответствующие дни.
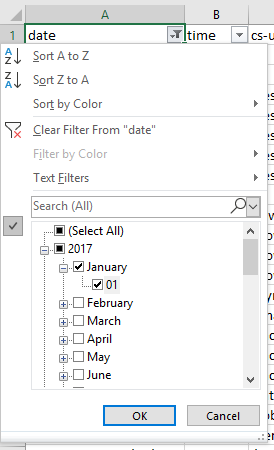
Частота обхода в зависимости от директивы
Для любого аудита сайта важно понимать, какие директивы для ботов соблюдаются. Например, если сайт запрещает обход адресов фасетной навигации, вам следует проверить, соблюдают ли краулеры этот запрет. Если нет — нужно прописывать соответствующие директивы на странице (meta robots).
Чтобы соотнести частоту и исполняемую директиву, нужно объединить отчет о сканировании сайта с логом:
- Выгрузить отчет о сканировании сайта (можно, например, из Screaming Frog SEO Spider).
- Экспортировать внутренний HTML-отчет (Internal Tab > Фильтр: HTML > internal_all.xlxs).

Здесь можно отфильтровать столбец по состоянию индексирования и удалить все пустые ячейки. Для этого используйте условие “Не содержит”. Также добавьте оператор “и” и отфильтровать все урлы с редиректами. Условие “Не содержит” > “Redirected”.
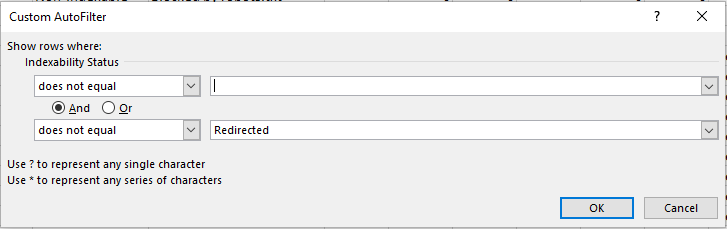
Далее копируем столбцы с адресом и состоянием, вставляем на чистый лист, куда будем экспортировать данные по анализу логов.
Теперь немного магии. Нужно убедиться, что данные по URI и URL представлены в том же формате, что и данные по обходу адресов.
В логах обычно URL не содержит корневой каталог и протокол. Поэтому нужно либо удалить эти данные из таблицы с данными по ободу (“Найти и заменить”), либо создать новый столбец на листе анализа файла с логами, добавить к нему протокол и корневой каталог. Я предпочитаю этот метод, потому что тогда можно быстро скопировать проблемный URL и посмотреть, что с ним не так.
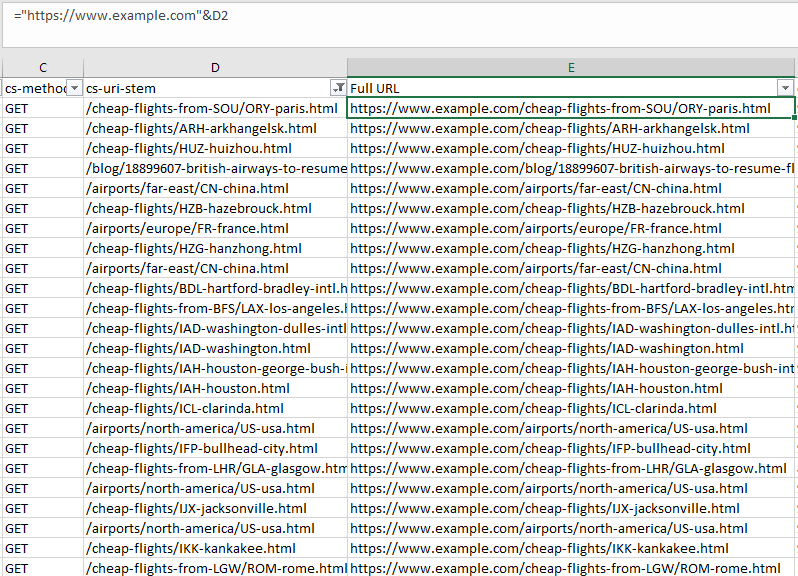
Чтобы получить полные адреса, используйте следующую формулу. Не забудьте поставить адрес вашего сайта и нужную ячейку.
="https://www.example.com"&D2
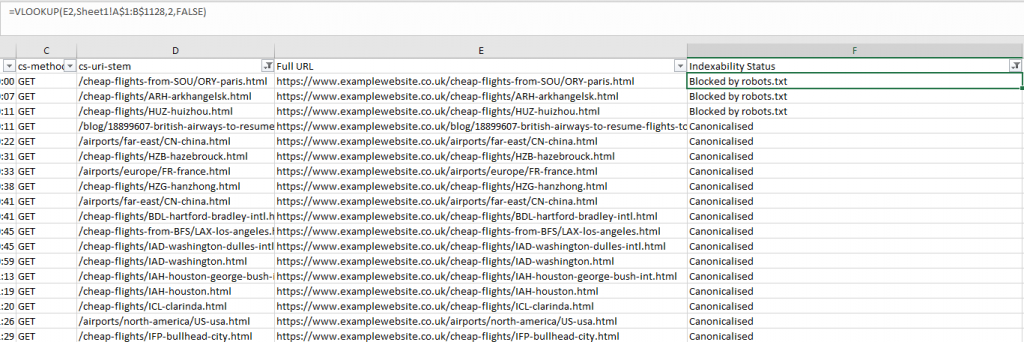
Теперь в новом столбце “Статус индексации” используем формулу VLOOKUP:
=VLOOKUP(E2,CrawlSheet!A$1:B$1128,2,FALSE)
Замените E2 первой ячейкой вашего столбца.
Затем выберите правильный столбец (1 — первая колонка таблицы индексирования, 2 — тот, который мы ищем).
Частота обхода по глубине и внутренним ссылкам
Этот анализ покажет структуру сайта с точки зрения расходования бюджета на сканирование. Основная цель — сколько у вас URL-адресов (и если их гораздо больше, чем лимит на обход, у вас проблемы).
Для начала любым инструментов просканируйте сайт. Экспортируйте отчет. Нам нужны данные по глубине клика и количеству внутренних ссылок для каждого URL.
В моем случае использован Screaming Frog.
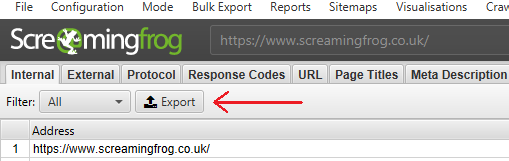
Далее используем функцию VLOOKUP, чтобы настроить соответствие между глубиной обхода, количеством ссылок и адресами.
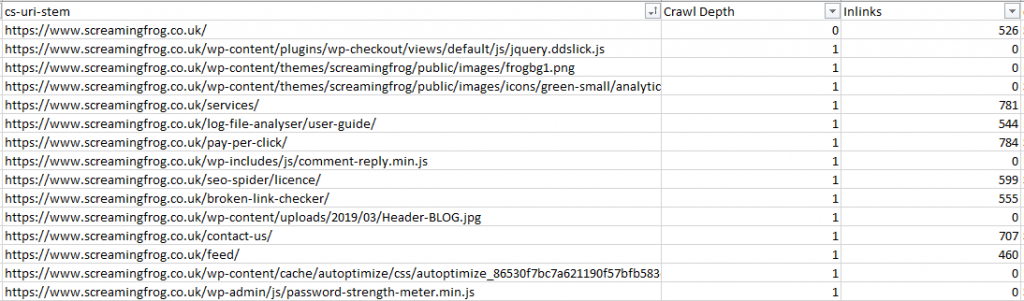
В зависимости от типа данных, которые будем смотреть, можно отфильтровать те адреса, которые возвращают код ответа 200, или сделать это вообще одним из параметров фильтрации данных.
Для сайтов электронной коммерции можно сосредоточиться только на URL продуктов. А если вы оптимизируете обход изображений, нам нужно поле Content Type из сводной таблицы.
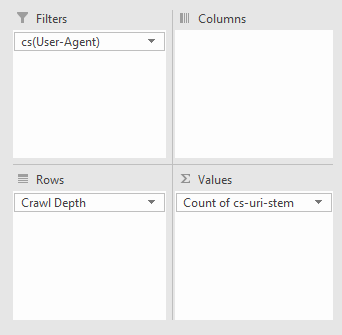
Настраиваем фильтр:
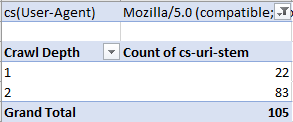
И получаем что-то такое:
Ищем проблемы со сканированием
Ошибки обхода
Очевидная и быстрая проверка. Все, что нужно сделать — отфильтровать столбец состояния (в моем случае sc-status) на наличие ошибок 4хх и 5хх.
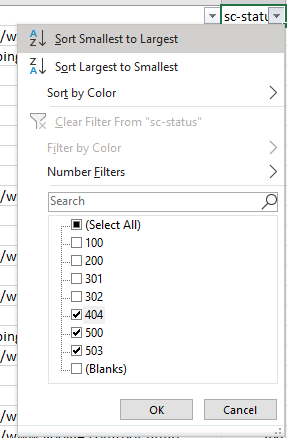
Поиск противоречий в ответах сервера
Конкретный URL может иметь разные коды ответа от сервера в разное время. Это может быть как нормальным поведением, когда исправили нерабочую ссылку, либо сигнал, что не все в порядке с сервером. Например, когда на сервер идет серьезная нагрузка по трафику.
Отсортируем поля по дате:
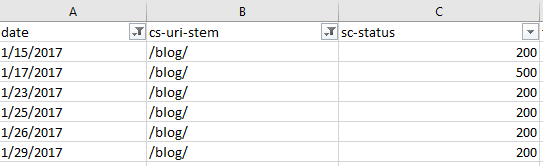
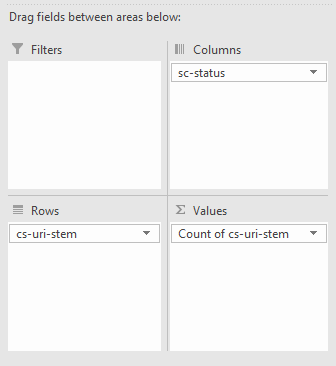
В качестве альтернативы, как меняются для одного урла коды ответа можно вытащить из сводной таблицы со следующими настройками:
И результат:
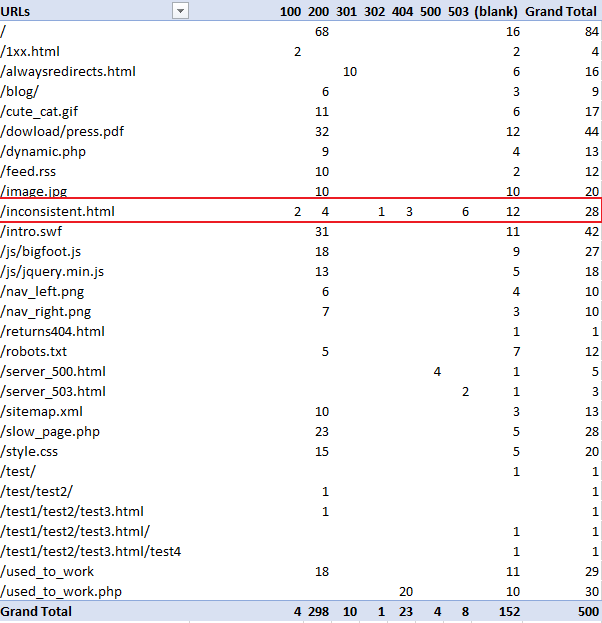
То, что выделено красным, имеет разные коды ответа.
Ошибки в директориях
Здесь будем искать проблемные подкаталоги. Отфильтруйте столбец URI (cs-uri-stem) по условию “содержит” и выберите конкретный каталог.
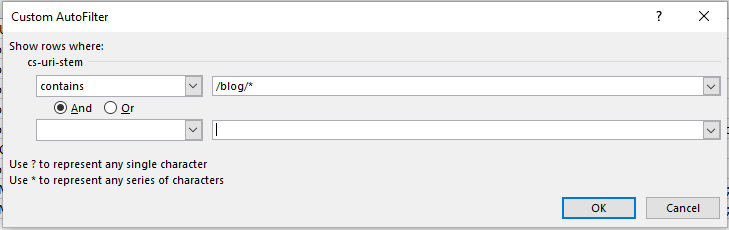
Я проверил у себя подкаталог блога и вот что нашел:
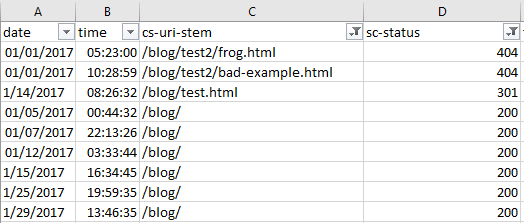
Ошибки по user-agent
Выяснение, у каких интерфейсов возникают проблемы полезно, когда вы работаете над производительностью сайта.
Можно посмотреть конкретные адреса, которые вызывают проблемы у конкретного бота. Самый простой способ — сводная таблица, в которой мы настроим фильтрацию по количеству раз, которое каждый код ответа встретится нужному URI.
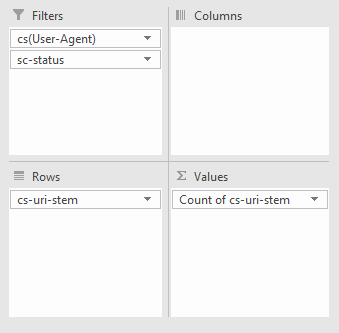
Далее можем отфильтровать по нужному боту и типу кода ответа сервера, например, ниже я смотрел урлы с 404 ошибкой для Googlebot:
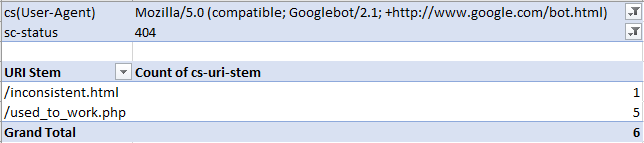
Кроме того, можно посмотреть, сколько раз конкретный бот генерирует разные коды ответов. В таблице придется считать число вхождений URI и коды ответов для конкретного робота. Сделать можно вот так:
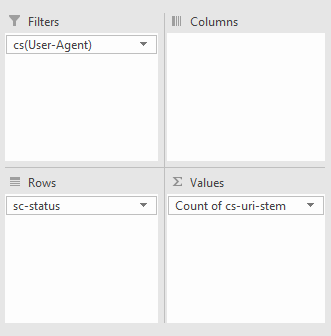
В примере ниже я смотрел, количество всех кодов ответа для googlebot:
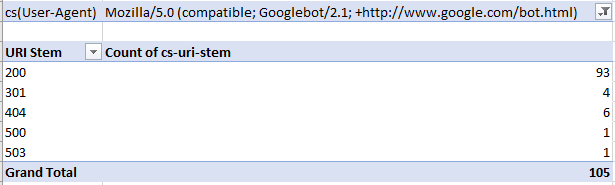
Ищем проблемы на страницах
Скажу противоречивую вещь: сайты должны быть не только для людей, но и для роботов. Страницы должны быстро загружаться, не должны слишком часто загружаться. В файле логов мы можем найти обе эти метрики для каждого URL-адреса с точки зрения поискового бота.
Поиск медленных и объемных страниц
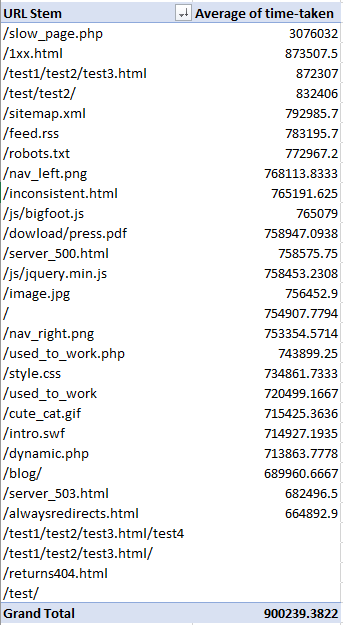
Можно, конечно, просто отсортировать лог по значению столбца “Время выполнения” и найти медленные страницы. Но лучше посмотреть на среднее время загрузки конкретного урла, потому что могут быть и другие факторы, которые влияют на то, что запрос исполняется медленно.
Создаем сводную таблицу. Строки — это URI, значение — суммарное время:
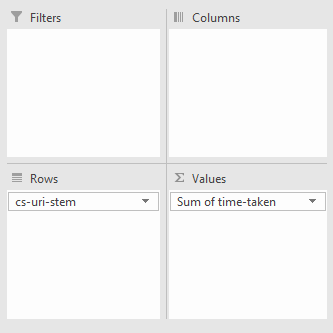
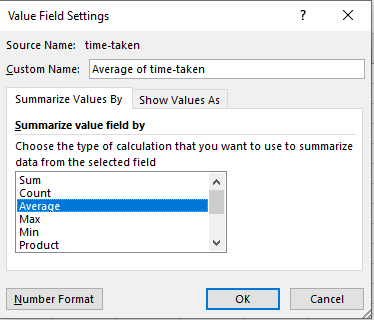
Далее для поля Sum of time-taken заходим в Настройки поля:
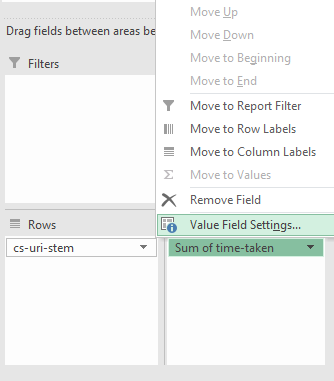
Выбираем “Среднее”.
И получаем вот такие данные:
Поиск емких страниц
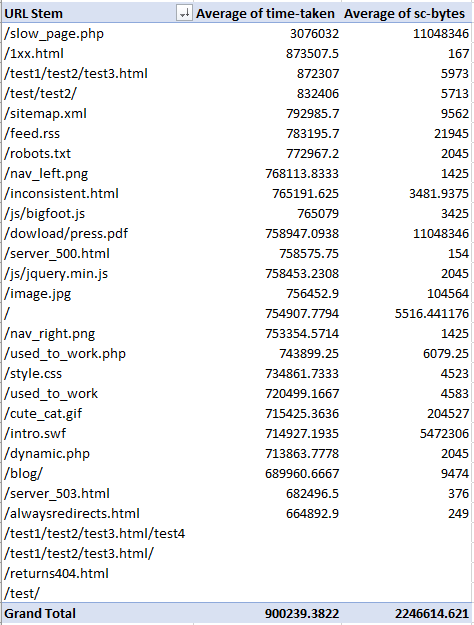
Теперь добавим столбец с размером загружаемых данных (sc-bytes). Помните, что в зависимости от цели, нужно выбирать либо среднее значение, либо сумму всех полей:
Результат:
Логи сервера — совсем не страшно!
Имея под рукой несколько простых инструментов, вы сможете глубоко погрузиться в анализ поведения поисковых роботов. Когда вы понимаете, как роботы сканируют сайт, где возникают проблемы, вы можете быстрее их решить.
Как следствие — улучшить присутствие сайта в органической выдаче.




