

Google похож на Гарри Гудини. С той же легкостью, с какой иллюзионист прятал слона от восторженной публики, поисковик обрабатывает триллионы страниц, чтобы за доли секунды ответить на ваш запрос. Как он это делает? Узнайте из нашей адаптации статьи Эрика Энжа.
Знаете ли вы, как поисковые системы, например Google, ищут, сканируют и ранжируют триллионы веб-страниц, чтобы показывать результаты, которые вы видите, когда вводите запрос.
Детали процесса достаточно сложные, однако знание основ (не технических) может помочь вам понять методы, стоящие за стратегией поисковой оптимизации.
Серьезное предприятие
На момент написания статьи Google утверждал, что знает более 130 триллионов страниц в интернете. Скорее всего, цифра намного больше. Есть много страниц, которые поисковик не сканирует, не индексирует и не ранжирует по многим причинам.
Для того чтобы сохранить результаты как можно более релевантными для пользователей, поисковые системы используют определенный процесс для идентификации лучших веб-страниц по каждому запросу. Со временем этот процесс развивается и делает результаты еще лучше.
Он включает в себя следующие шаги:
- Сканирование.
- Индексирование.
- Ранжирование.
Подробнее рассмотрим упрощенное описание каждого из них.
Сканирование страницы
У поисковых систем есть краулеры (пауки), которые сканируют мировую паутину с целью поиска страниц, наиболее подходящих под запрос. Метод, при помощи которого краулеры передвигаются по страницам – ссылки на сайт.
Ссылки связывают между собой страницы и сайты всемирной паутины и таким образом создают путь, по которому пауки передвигаются по триллионам существующих взаимосвязанных страниц.
Визуальный пример? Ниже представлен скан страницы Государственного музея изобразительных искусств имени А.С. Пушкина:
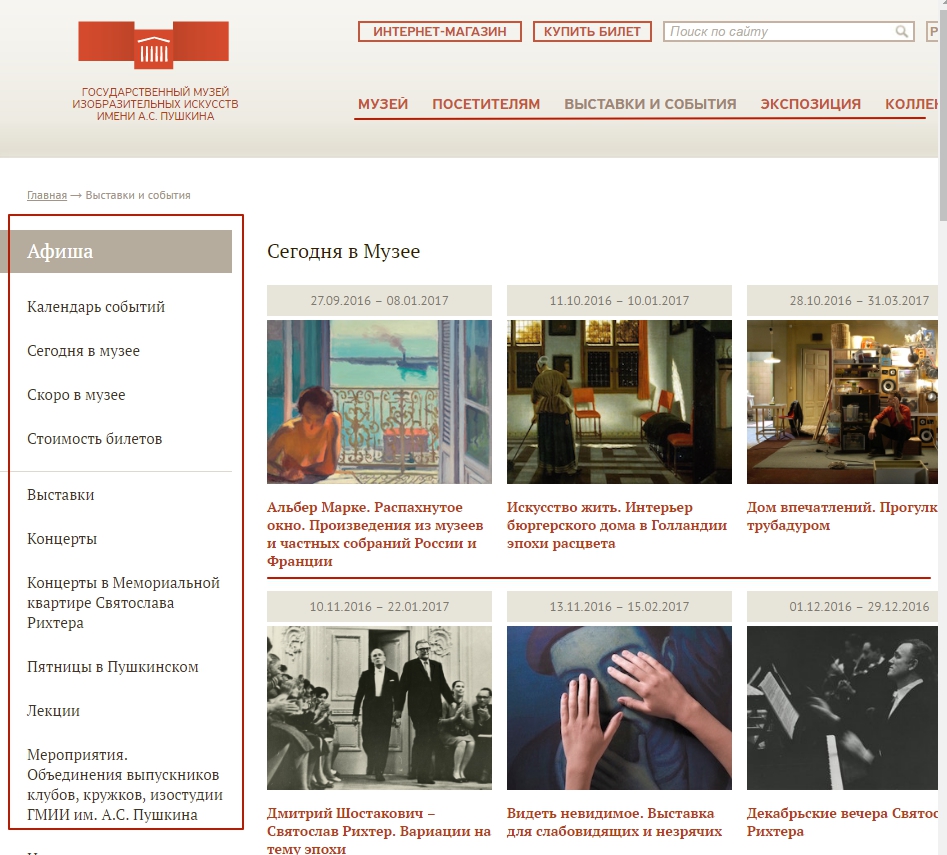
Всякий раз, когда краулеры оказываются на информационном ресурсе, они просматривают его «Document Object Model» (или «DOM»), чтобы увидеть содержимое.
DOM – это преобразованный HTML и JavaScript страницы, позволяющий паукам просматривать одни страницы сайта в поисках ссылок на другие (на картинке выделено красным). Это дает поисковой системе возможность обнаруживать новые информационные ресурсы. Каждая найденная ссылка загружается в очередь для последующего посещения краулером.
Ежедневное сканирование всего интернета было бы слишком большим предприятием, поэтому обычно Google запускает паука с периодичностью в несколько недель. Кроме того, как я упомянул раньше, поисковые системы не сканируют каждую существующую страницу.
Вместо этого, они начинают с набора сайтов, которым уже доверяют. Эти веб-ресурсы служат в качестве основы для определения соответствия других сайтов. Следуя по ссылкам, которые роботы видят на посещаемых страницах, они распространяют пауков по всему интернету.
Индексация данных
Индексация – это операция по добавлению информации о странице в индекс поисковой системы. Индекс – это коллекция веб-страниц (база данных), включающая информацию о ресурсах, просканированных пауками поисковой системы.
Индекс каталогизирует и организует:
- Подробные данные о природе контента и его актуальности по каждой странице.
- Карту всех страниц, связанных ссылками.
- Анкорные тексты каждой ссылки.
- Другую информацию о ссылках, в том числе являются они рекламными или нет, где расположены, а также что они означают для страницы, получившей ссылку.
- И многое другое.
Индекс – это база данных, с помощью которой поисковые системы хранят и извлекают информацию по запросу пользователя. Перед тем как решить, какие страницы из индекса показать и в каком порядке представить их в выдаче, поисковые системы применяют алгоритм, позволяющий ранжировать эти страницы.
Индексы поисковых систем – это, на самом деле, база данных с разнообразной информацией о странице.
Ранжирование результатов
Чтобы предоставить результаты пользователю, поисковые системы должны сделать некоторые важные шаги:
- Интерпретировать намерение пользователя по запросу.
- Идентифицировать в индексе веб-страницы, связанные с запросом.
- Ранжировать и вывести их в соответствии с важностью или релевантностью.
Это одна из основных областей, с которой начинается поисковая оптимизация.
Эффективная SEO стратегия влияет на релевантность и важность веб-страниц по связанным вопросам.
Что значит релевантность и важность?
- Релевантность
Это степень, в которой контент на веб-странице соответствует намерениям пользователя (намерение – это то, чего юзер пытается достигнуть этим поиском, что, как вы понимаете, узнать поисковику не так легко).
- Важность
Чем больше цитируется страница, тем более важной она считается (поэтому можете рассматривать ссылки в качестве вотума доверия).
Чтобы выполнить задачу по присвоению актуальности и важности странице, поисковые системы используют сложные алгоритмы, способные учитывать сотни сигналов.
Поисковые системы ранжируют страницы в соответствии с их релевантностью и важностью.
Поисковые системы работают над улучшением методов отбора лучших результатов по запросам пользователей, поэтому алгоритмы часто меняются.
Но даже несмотря на постоянные изменения, некоторые фундаментальные принципы достаточно хорошо изучены.
Хотя мы, возможно, никогда не узнаем полный список сигналов, которые используют роботы (это секрет под семью замками, и не зря, ибо таким образом спамеры не могут использовать эти знания для обмана системы), основная информация распространяется, и мы можем использовать ее для создания долгосрочных SEO стратегий.
Как поисковые системы оценивают контент
В рамках ранжирования, поисковые системы должны понимать природу контента каждой просканированной страницы. На самом деле, Google уделяет большое внимание наполнению веб-страницы. Он использует контент как сигнал ранжирования.
В 2016 году Google подтвердил то, во что многие из нас давно верили: контент входит в топ-3 факторов ранжирования веб-страниц. Чтобы понять тематику информационного ресурса, поисковик анализирует слова и фразы, которые представлены на нем, а затем составляет карту данных, известную как «семантическая карта». Она помогает определять отношения между концептами на веб-странице.
Поисковики создают семантические карты для того, чтобы понять и оценить контент на странице.
Вам может быть интересно узнать, что такое «контент» веб-страницы. Посмотрим пример.

Как вы можете заметить на изображении выше, уникальный контент страницы состоит из таких вещей, как:
- Заголовок.
- Основной контент.
На картинке они отмечены красным.
Если на странице есть навигационные ссылки, то они, как правило, в контент не входят. Это не значит, что они не важны, но в данном случае они не считаются уникальным содержанием страницы.
Что поисковые системы могут увидеть на странице?
Для того, чтобы оценить контент, поисковые системы выполняют парсинг сайтов.
Поскольку поисковики – это компьютерные программы, они «видят» страницы не так, как мы.
Краулеры поисковых систем рассматривают веб-страницы в виде DOM (как мы уже говорили выше). Но у вас есть возможность узнать, что видит поисковик. Как? Посмотреть код страницы, щелкнув по ней правой кнопкой мыши. У вас должно получиться нечто подобное:
Разница между тем, что видим мы, и DOM есть. Однако вы всё равно можете использовать информацию, полученную из кода. Например, чтобы узнать больше о контенте. Основное содержимое страницы представлено в коде:
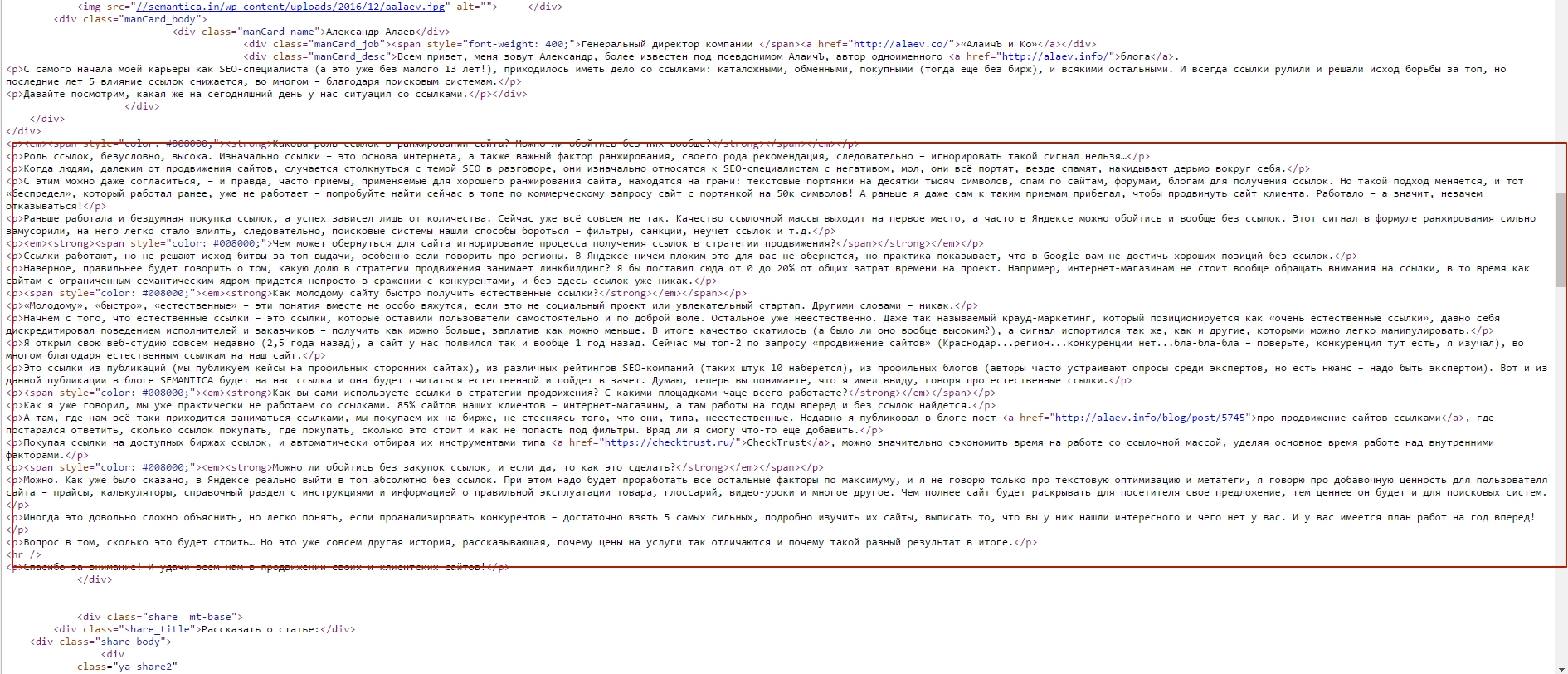
Помимо уникального контента, есть другие элементы, которые помогают паукам поисковых систем понять, о чем страница.
В том числе:
- Метаданные – тайтл, дескрипшн, обнаруженные в коде HTML. Хотя они не так легко доступны со страницы, их можно увидеть в результатах поиска в виде тайтла и описания ресурса в выдаче. Поэтому их содержимое должно контролироваться владельцами веб-сайта.
- Атрибут alt для изображений на веб-странице. Это описание, которое рассказывает, что на картинке. Поскольку поисковики не могут увидеть изображения, описание поможет им лучше понять контент на странице и сыграет важную роль для людей с ограниченными возможностями, которые используют программы для чтения с экрана для описания содержимого веб-страницы.
Что поисковые системы не могут увидеть на странице?
Чтобы сделать контент легко доступным поисковым роботам, важно знать, какие элементы от них скрыты.
Мы уже упомянули изображения и сказали о роли атрибута alt в помощи поисковику понять, о чем картинка. Другие элементы, которые поисковик не видит, включают:
- Flash-файлы
Представители Google заявляли, что система может извлекать некоторую информацию из файлов Adobe Flash, но это сложно, потому что Flash – изобразительное средство. Когда дизайнеры используют Flash для разработки дизайна сайта, они, как правило, не вставляют текст, который объяснял бы о чем сайт.
- Аудио и видео
Как и в случае с картинками, поисковым системам тяжело понимать, что на видео или аудио без контекста. Есть несколько исключений, при которых поисковые системы могут извлекать ограниченную информацию в тегах ID3 например, через Mp3 файлы. Это одна из причин, почему многие сопровождают аудио и видео транскрипцией на странице, чтобы помочь поисковикам оценить информацию.
- Содержание, включенное в программу
Сюда входят AJAX и другие формы методов JavaScript, которые динамически загружают контент на страницу. Google говорил, что сейчас может достаточно хорошо читать JavaScript, но все равно некоторые ограничения есть. Будет справедливо сказать, что Google выполняет большинство сценариев JavaScript, но иногда возникают проблемы, основанные на реализации.
- Iframes
Этот тег обычно используется для встраивания контента, взятого из других источников в интернете, в текущую страницу. Google может не рассматривать этот контент как часть вашей страницы, особенно, если он взят со стороннего сайта. Так сложилось, что Google игнорировал контент, заключенный в iframe, но бывали исключения из правила.
Итоги
Работа поисковых систем выглядит очень простой: введите запрос в строке поиска и вуаля! Вас ждут результаты. Но это мгновенное удовольствие приводится в действие комплексом сложных настроек, которые помогают идентифицировать наиболее релевантные данные для конечного пользователя.
Почему вас должно это заботить?
Знание фундаментальных принципов сканирования, индексирования и ранжирования помогает владельцам веб-ресурсов лучше настраивать свои сайты, а поисковикам читать и понимать контент, улучшая результаты поиска.



