
Многие говорят, что использование LSI-ключей в тексте помогает выводить запросы в топ и получать больше трафика из поисковых систем. Сегодня будем разбираться, правда ли это или очередной миф.
Откройте любую статью про LSI и увидите в ней:
- что Google использует технологию для индексации страниц;
- соответственно, использование LSI-запросов в тексте повышает рейтинг страницы.
Оба утверждения не верны.
- Что такое LSI-запросы
- Что такое латентно-семантическое индексирование?
- Принцип работы LSI
- Использует ли Google LSI: 3 аргумента, почему нет
- Как влияют синонимы и близкие по смыслу слова на ранжирование
-
Как найти связанные ключевые слова
- 1. Используйте здравый смысл
- 2. Посмотрите на результаты автозаполнения
- 3. Посмотрите на поисковые подсказки
- 4. Используйте LSI keyword tool
- 5. Посмотрите на семантику страниц из топа
- 6. Проведите TF-IDF-анализ
- 7. Посмотрите в базу знаний
- 8. Проведите обратный инжиниринг графа знаний
- 9. Воспользоваться Google’s Natural Language API
- Заключение
Что такое LSI-запросы
Речь про латентно-семантическое индексирование. Google использует семантически близкие слова к поисковой фразе, чтобы лучше понимать степень релевантности страницы запросу. По крайней мере, так говорят в SEO-сообществе. Если говорим про автомобили, то LSI-словами будут: двигатель, мотор, дорога, техника, моторное масло и т. д.
Согласно заявлению Джона Мюллера, LSI-слов не существует:
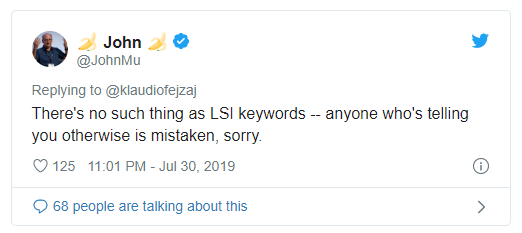
И что теперь делать? Для ответа давайте разбираться, как все работает.
Что такое латентно-семантическое индексирование?
Латентно-семантический анализ — техника обработки естественного языка. Ее разработали ученые в 1980 году.
Если вы не знакомы с математическими понятиями и не знаете, что такое собственные значения, векторы и разложения по отдельным значениям, разобраться будет непросто.
Создатели технологии так описывали проблематику: запросы, которые использует человек, часто не совпадают со словами, которыми можно дать ответ, в т. ч. на странице сайта.
Представьте, что у вас отключили интернет, и вы идете в библиотеку за большим словарем. Чтобы не листать тысячи страниц, вы находите в путеводителе нужное слово и открываете нужную страницу. Нужно слово «fall»? Вот, что вы увидите:

Не то, что нужно. В английском языке слова fall и autumn (осень) — синонимы. Нужно открыть другую страницу:

Проблема в том, что слово, которое мы ищем — многозначное. В русском языке, например, есть «замок» — в значении крепости или в значении запирающего механизма.
Подробнее про синонимы
Синонимы — это слова или фразы, которые означают близкие по смыслу объекты (или одинаковые), но при этом друг на друга не похожи совершенно. Крепость — это замок, твердыня, форт.
Вот, почему работа с синонимами проблематична: люди могут описывать один и тот же объект разными словами — в силу словарного запаса, в зависимости от контекста или места проживания.
Но как это относится к поисковым системам? Предположим, у нас есть две страницы про автомобили. Они одинаковы, но на одной везде вместо слова «автомобиль» — «машина».
Если использовать примитивную поисковую систему, которая индексирует только конкретные слова и фразы на странице, по запросу «машина» мы увидим только одну страницу.
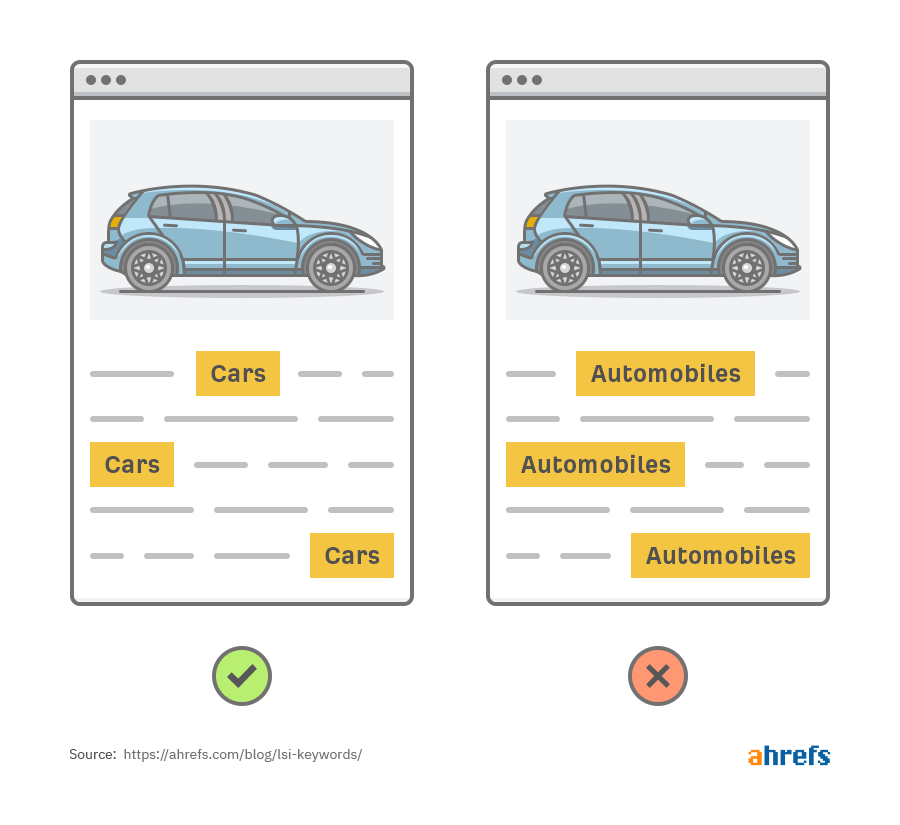
Это плохо, потому что оба результата релевантны запросу. Он описывает то же самое, но просто другими словами.
Итог: поисковикам нужно понимать синонимы, чтобы лучше отвечать на поисковые запросы.
Подробнее про многозначные слова
Многозначные слова и фразы: мышь (для компьютера и животное). Одинаковое слово может использоваться в совершенно разных значениях.
Отсюда и проблемы. В разных контекстах одно и тоже слово приобретает разное референтное значение. Так, использование такого слова в поисковом запросе может не всегда означать, что пользователю интересно именно то, что он видит в выдаче.
Так, по запросу «apple computer» можно увидеть совершенно разные страницы:
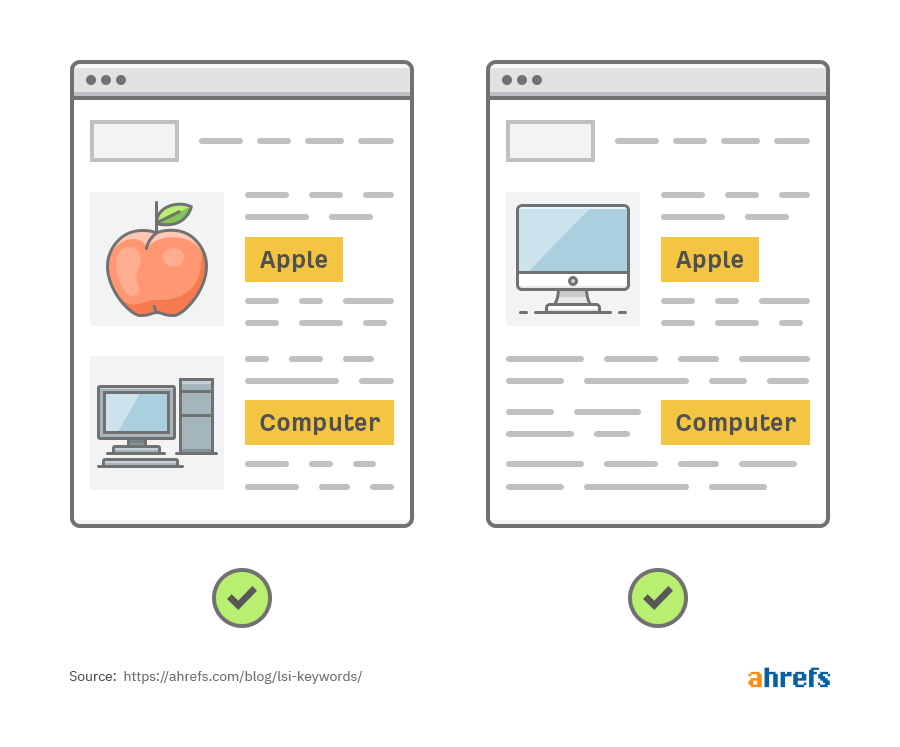
Итог: поисковые системы, которые не понимают различия между многозначными словами, скорее всего, выдадут нерелевантные ответы.
Принцип работы LSI
Компьютеры глупы.
Они не понимают словесные отношения, которое понятно людям. Например, очень большой и огромный — два разных слова, которые значат одно и то же. И все помнят, что Джон Леннон играл в Битлз.
Но у машины таких знаний нет. Проблема в том, что компьютеру невозможно рассказать все — на это уйдет слишком много времени и сил. LSi решает как раз эту проблему: технология использует математические формулы для получения связей между словами и фразами из набора документов.
Проще говоря, если применить метод к документам про смену времен года, компьютер сможет выяснить несколько моментов.
Например, что слова fall и autumn — синонимы:
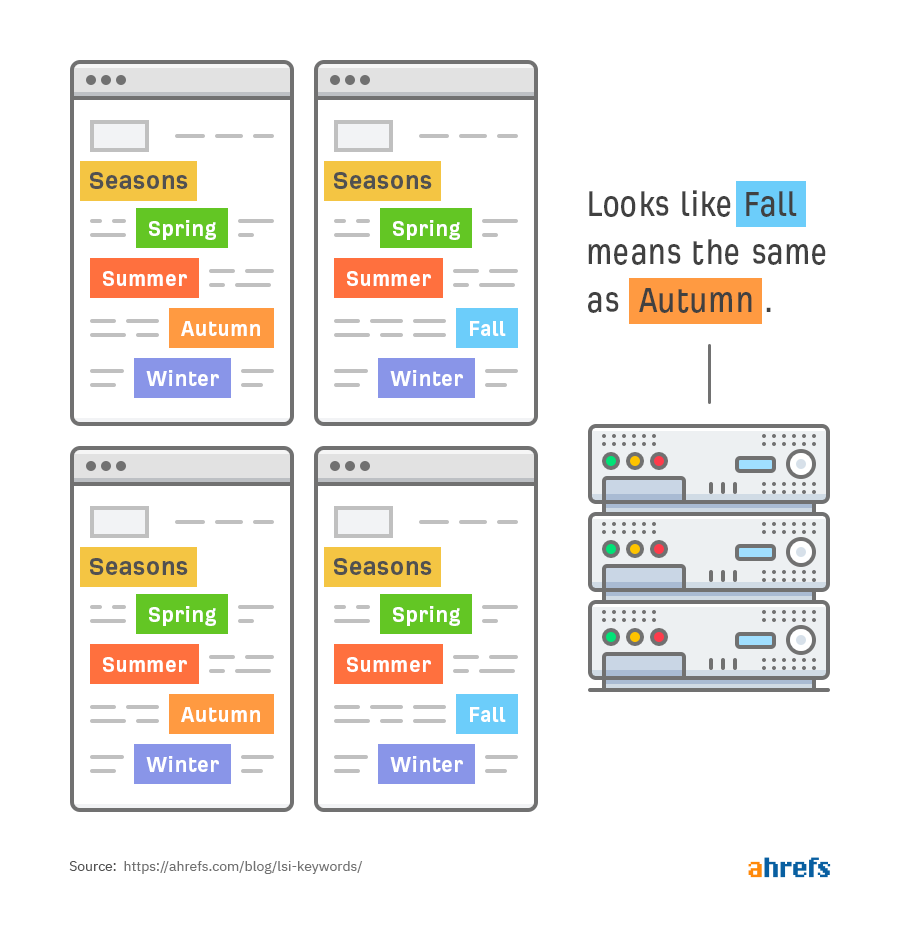
Второе: слова «сезон», «лето», «зима», «весна» — синонимически схожи, потому что используются для описания одного процесса — смены времен года.
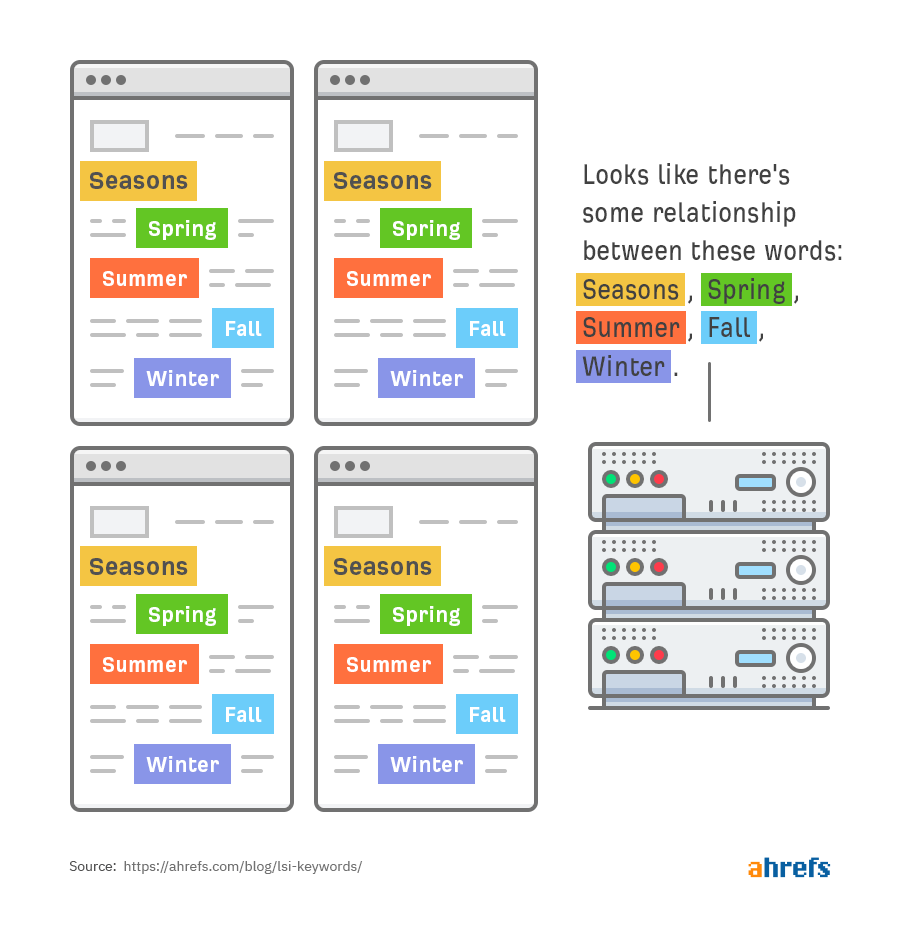
В-третьих, слово fall синонимически связано с двумя разными наборами слов:
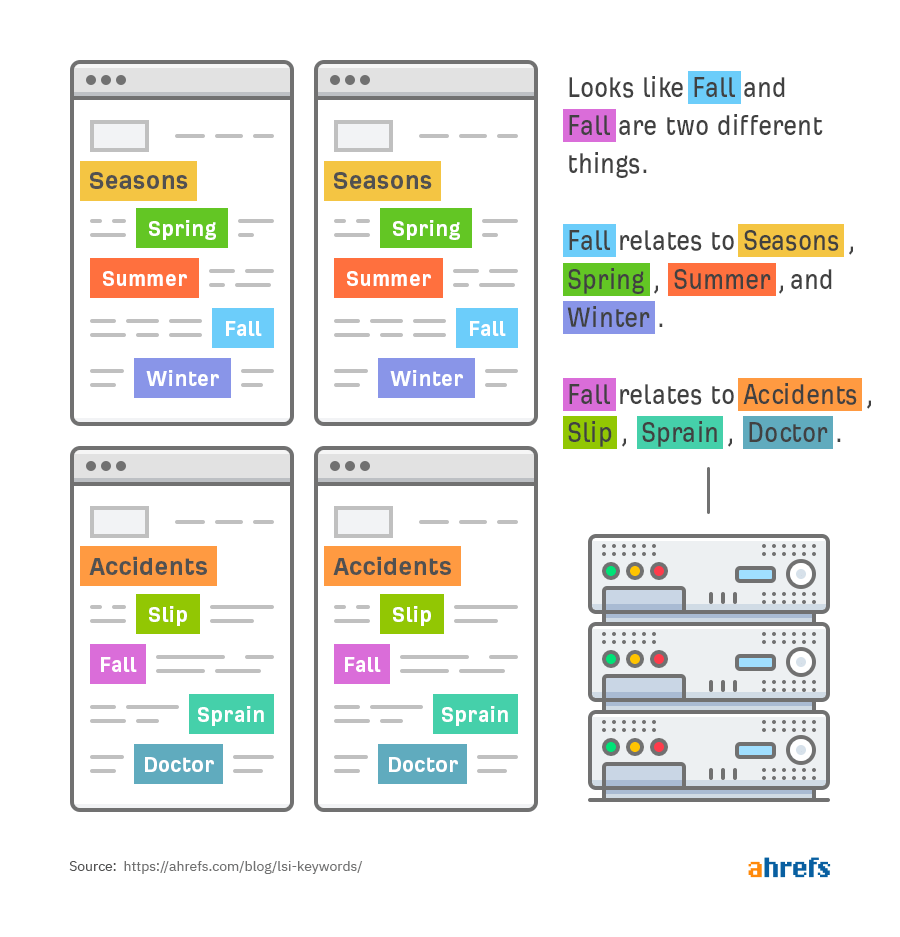
Затем поисковые системы могут использовать информацию, чтобы выйти за рамки точного соответствия и предоставить более релевантные результаты поиска.
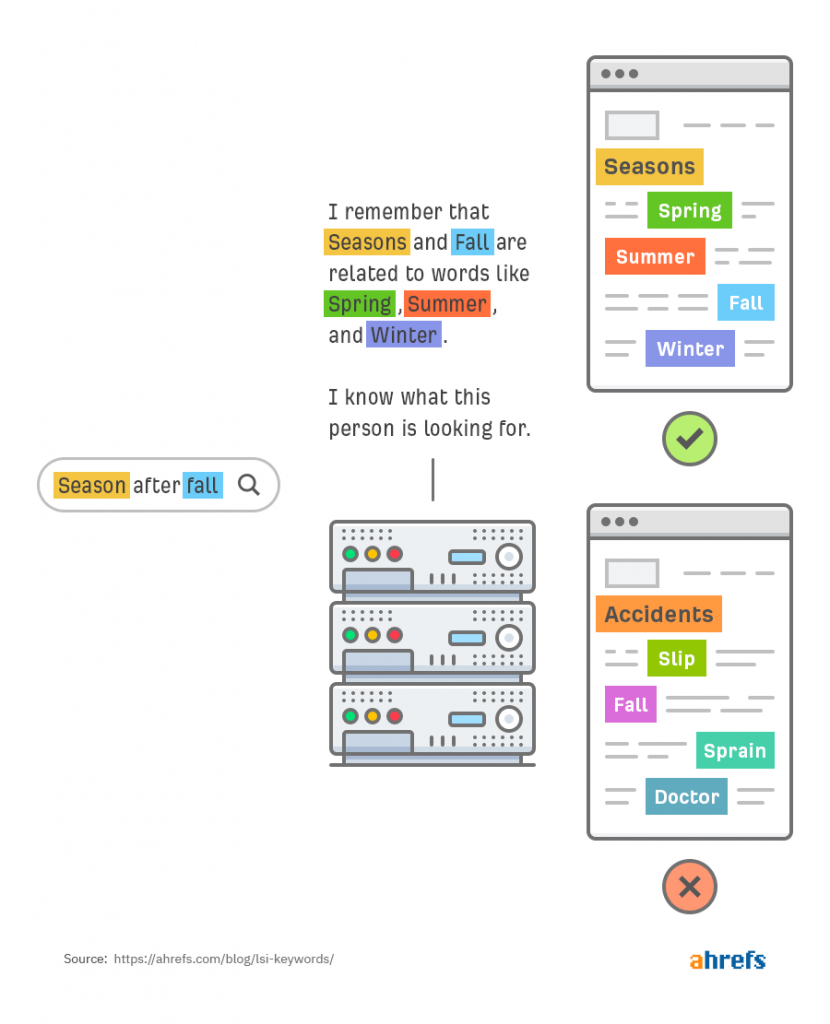
Использует ли Google LSI: 3 аргумента, почему нет
Учитывая проблемы, которые решает LSI, легко понять, почему многие считают, что Google использует эту технологию. В конце концов, очевидно, что сопоставление точных запросов — ненадежный способ предоставлять лучший ответ на вопрос.
Кроме того, мы ежедневно получаем доказательства, что Google понимает синонимы:
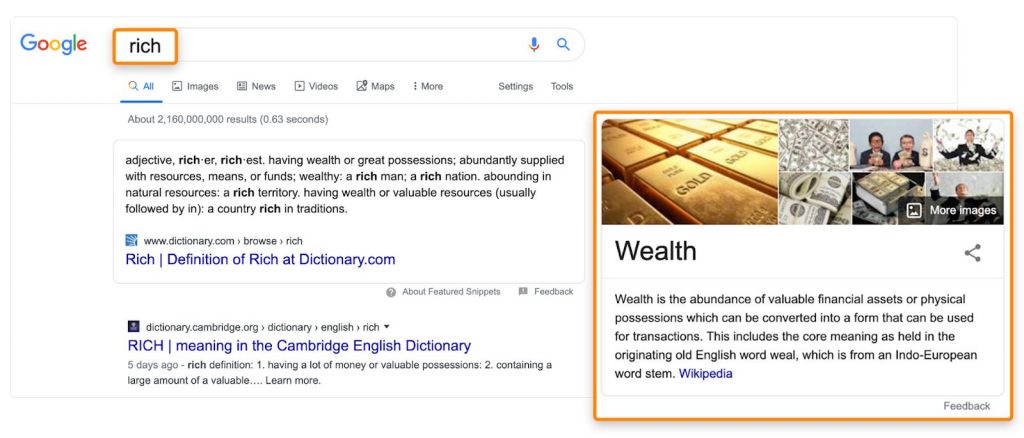
И многозначность:
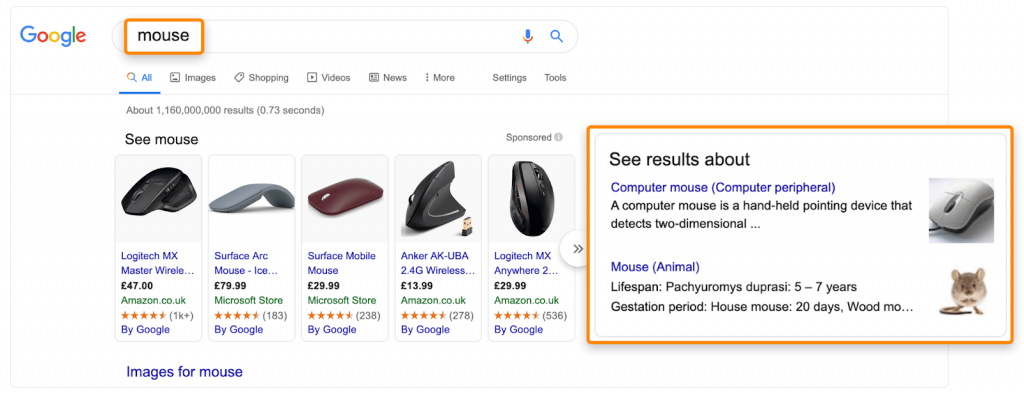
Но, скорее всего, дело не в LSI. Вот три доказательства, что система это не использует.
1. LSI — устаревшая технология
Технологию изобрели в 1980, когда не было интернета. Как таковая, она никогда не предназначалась для применения к такому большому набору документов.
Google разработал лучшую технологию, которую можно масштабировать. Она решает те же проблемы. Билл Славски говорит: LSI-технология не подходит для использования на такой большой выборке документов. У Google есть собственная модель, основанная на векторах — Rankbrain в том числе — она более современна.
2. LSI создана для работы с известными документами
Интернет не только большой, но и динамичный. Миллиарды страниц в индексе поисковика постоянно меняются.
Это проблема, потому что в патенте LSI есть упоминание: запускать анализ каждый раз, когда происходит существенное обновление файлов, которые хранятся в системе. Это занимает много вычислительной мощности.
3. Технология LSI запатентована
Патент на технологию получила компания Bell Communications Research Inc. в 1989 году. Сьюзан Дюма, которая работала над проектом, позже присоединилась к Майкрософт, где она работала над проектами, связанными с поиском информации.
Патент дается на 20 лет по законам США, а это значит, что его действие прекратилось в 2008 году.
Учитывая, что Google достаточно хорошо понимал язык запросов и давал релевантные результаты намного раньше 2008, можно сказать, что Google не использует LSI.
Как влияют синонимы и близкие по смыслу слова на ранжирование
Большинство оптимизаторов видят ключевые LSI-фразы как не более, чем связанные по смыслу сущности.
Если мы используем это определение — хотя оно технически неточное — тогда да, некоторые связные слова на странице могут улучшить SEO. Просто подумайте: когда вы вводите запрос со словом «собака», наверняка вам не понравится текст, где это слово упоминается сотню раз. Поисковик оценивает, содержит ли страница другое ключевое слово, которое относится к этой же тематике.
На странице о собаках Google видит названия отдельных пород как семантически связанные. Но почему разные слова помогают лучше ранжироваться этой странице? Все просто: потому что они помогают Google понять общую суть контента.
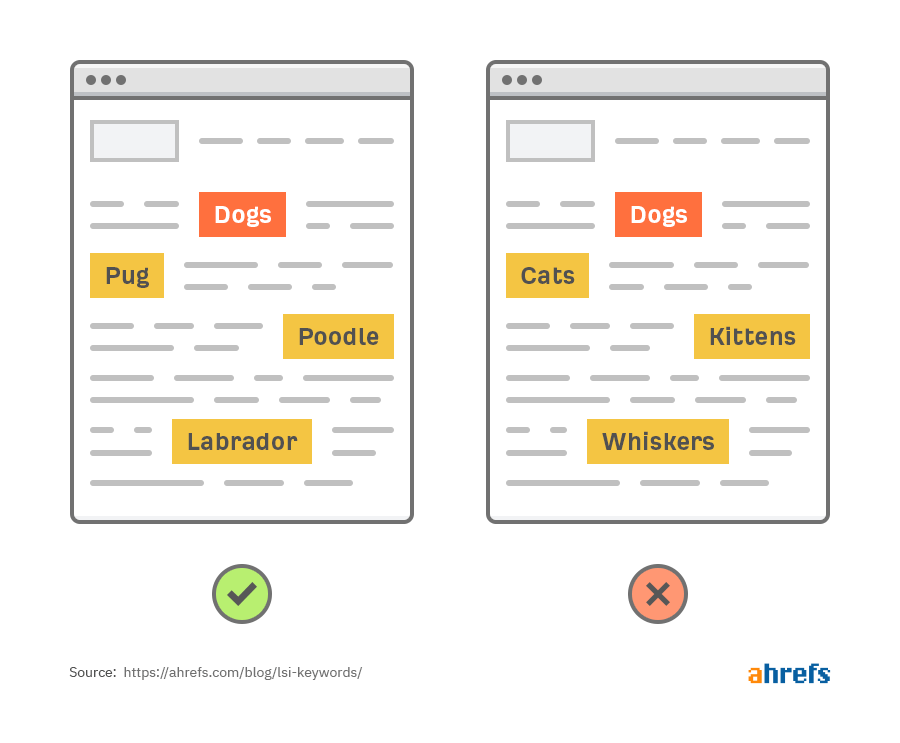
Глядя на другие важные слова и фразы на странице, мы узнаем, что только первая рассказывает именно о собаках.
Как найти связанные ключевые слова
Если вы хорошо разбираетесь в теме, вы естественным образом включите такие синонимы в свое СЯ.
Например, было бы сложно написать о лучших видеоиграх без упоминания фраз вроде «PS4 games», «Call of Duty», «Fallout». Но легко пропустить важные ключи с более сложными темами.
Например, в нашем гайде про nofollow нет ни слова про UGS или sponsored.
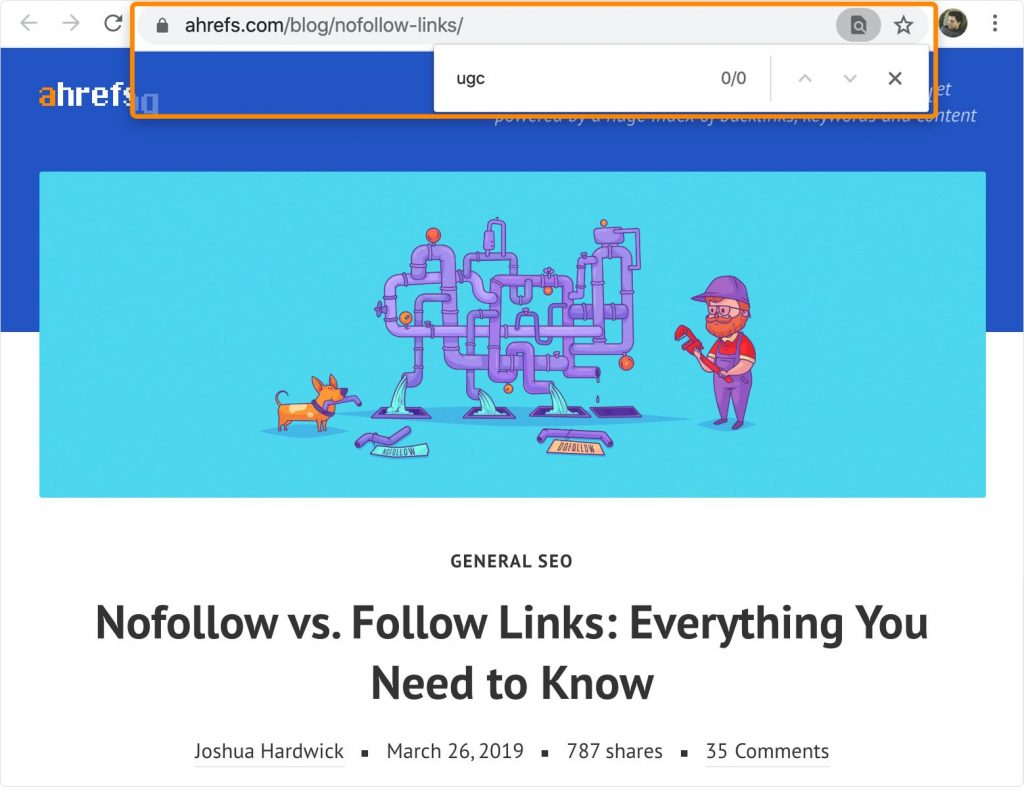
Google, вероятно, считает это важными семантически связанными терминами, которые следует упомянуть в любой хорошей статье по этой теме. Это может быть одна из причин, почему другие статьи про ссылки ранжируются лучше, чем наша.
1. Используйте здравый смысл
Проверьте свои страницы, чтобы увидеть, не пропустили ли вы ничего. Например, если пишете про биографию Дональда Трампа и не упоминаете его импичмент, вероятно, нужно добавить раздел про это.
2. Посмотрите на результаты автозаполнения
Результаты автозаполнения не всегда показывают важные фразы, но они могут дать подсказки, о чем обязательно нужно упомянуть в статье.
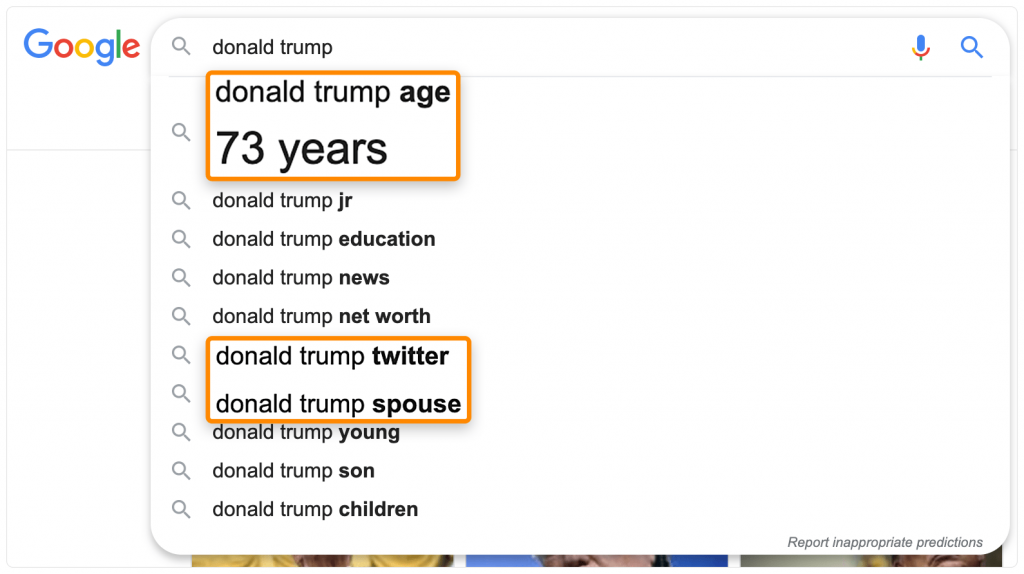
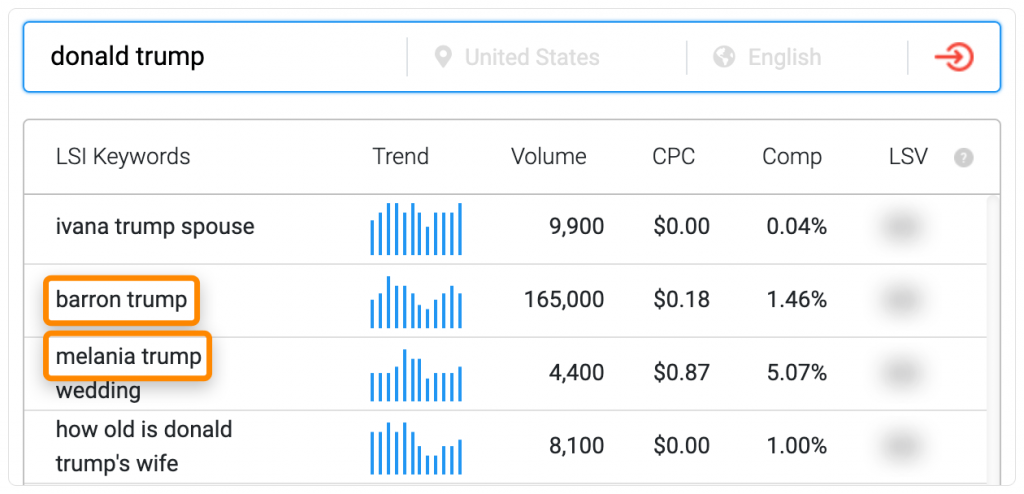
Сами по себе, выделенные слова не связаны между собой, но они относятся к основному запросу. Например, тут обязательно надо добавить раздел про его супругу Мелани.
3. Посмотрите на поисковые подсказки
Подсказки появляются под выдачей. Как и результаты автозаполнения, они могут помочь понять о связанных понятиях и объектах, про которые нужно рассказать.
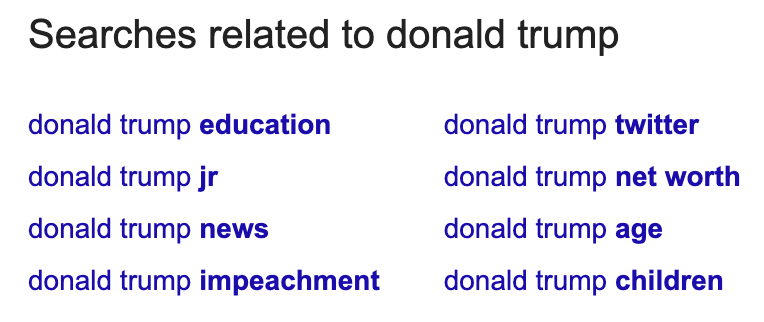
Здесь «donald trump education» относится к The Wharton School of the University of Pennsylvania, в которой он учился.
4. Используйте LSI keyword tool
Популярные генераторы :LSI не имеют ничего общего с настоящим LSI. Тем не менее, они иногда выдают некоторые полезные мысли.
Например, если мы введем «donald trump», сервис выдаст несколько полезных имен:
5. Посмотрите на семантику страниц из топа
Используйте отчет Also Rank For в Ahrefs, чтобы найти потенциально связанные друг с другом слова.
![]()
Есть еще инструмент Content Gap, который показывает, где в контенте на сайте есть пробелы, исходя из поисковой семантики.
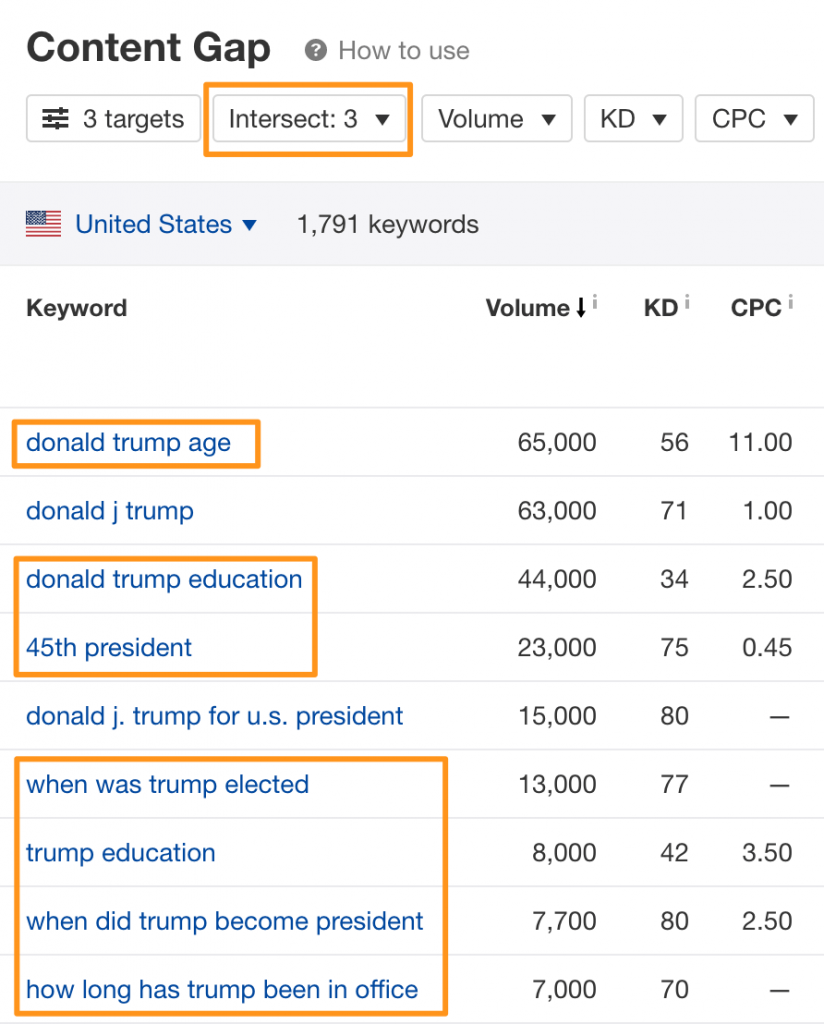
Здесь показаны те ключевые слова, по которым ранжируются все страницы из топа. Часто они дают более полный список всех запросов для статьи.
6. Проведите TF-IDF-анализ
TF-IDF не имеет ничего общего с LSI или LSA, но иногда помогает обнаружить пропущенные слова или сущности.
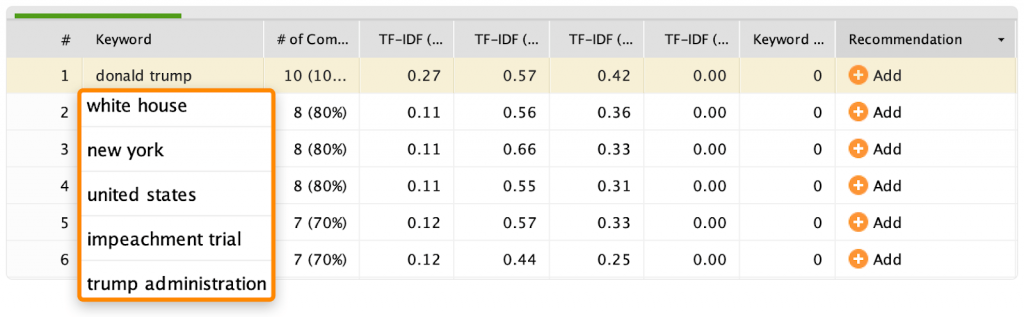
7. Посмотрите в базу знаний
Такие базы знаний, как Википедия или Викидата — просто фантастические источники терминов.Google извлекает отсюда информацию для своего графа знаний.
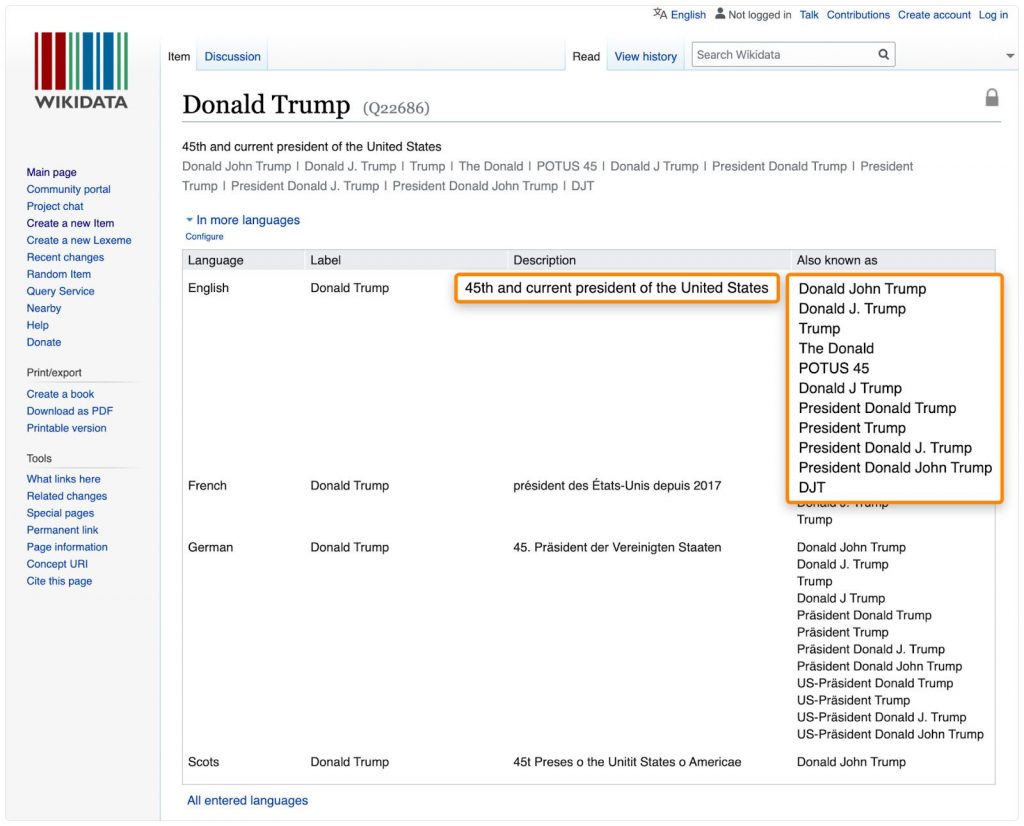
8. Проведите обратный инжиниринг графа знаний
Google хранит отношения между множеством людей, вещей и концепций в графе знаний. Результаты часто попадают в расширенные сниппеты.
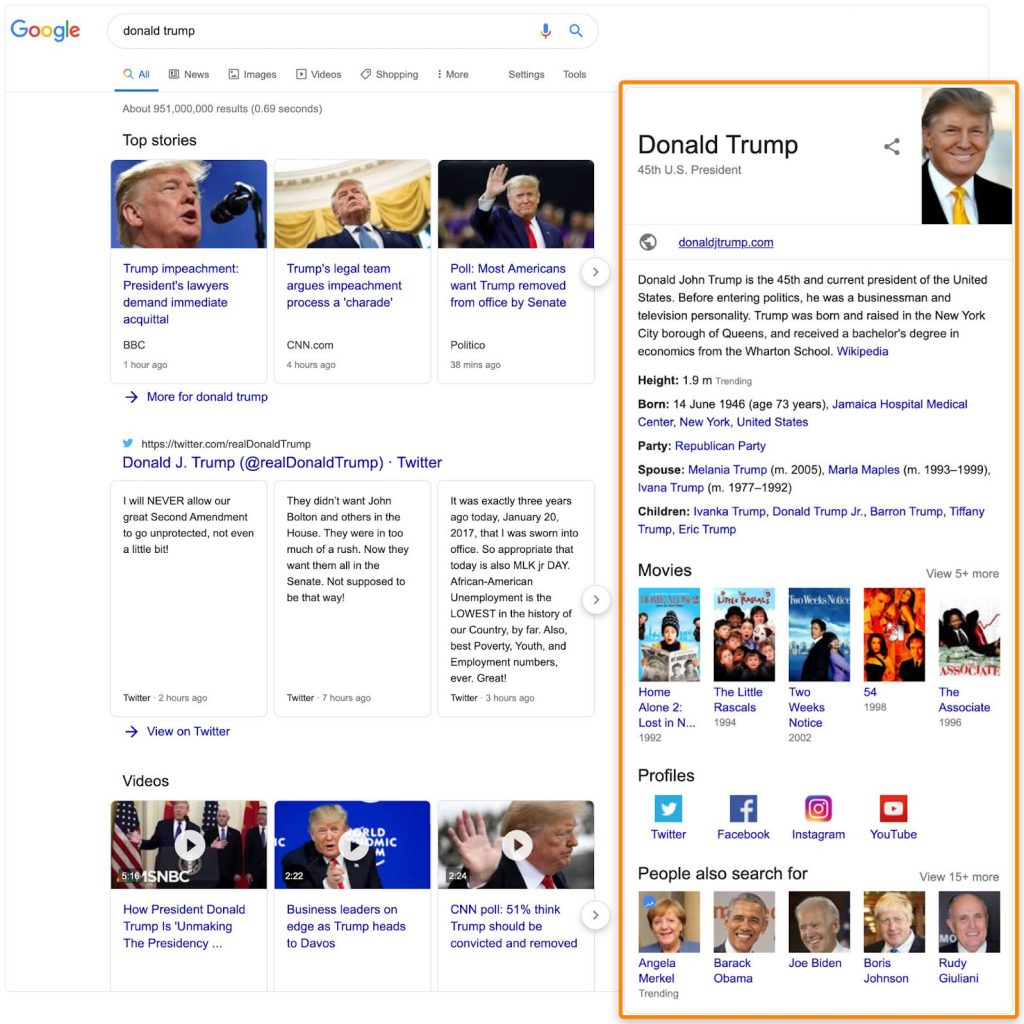
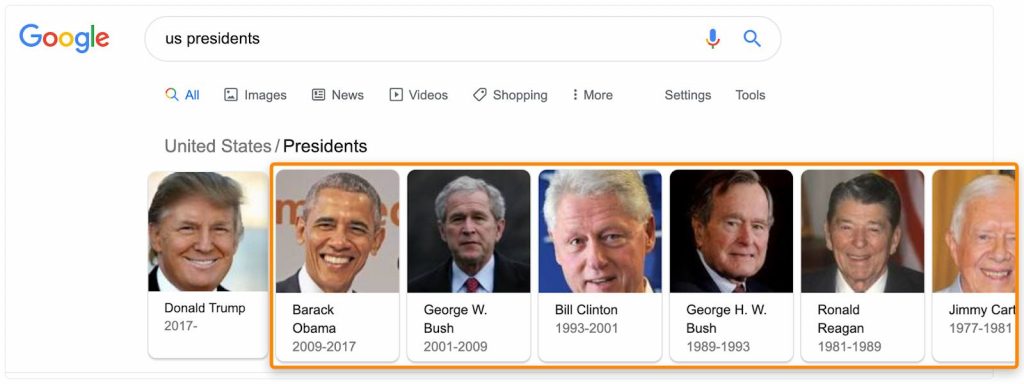
Попробуйте выполнить поиск по ключевому слову и посмотрите, есть ли какие-то данные из этого графа. Так как это термины, которые Гугл связывает друг с другом, определенно стоит поговорить о существующих словах, с которыми они могут быть связаны.
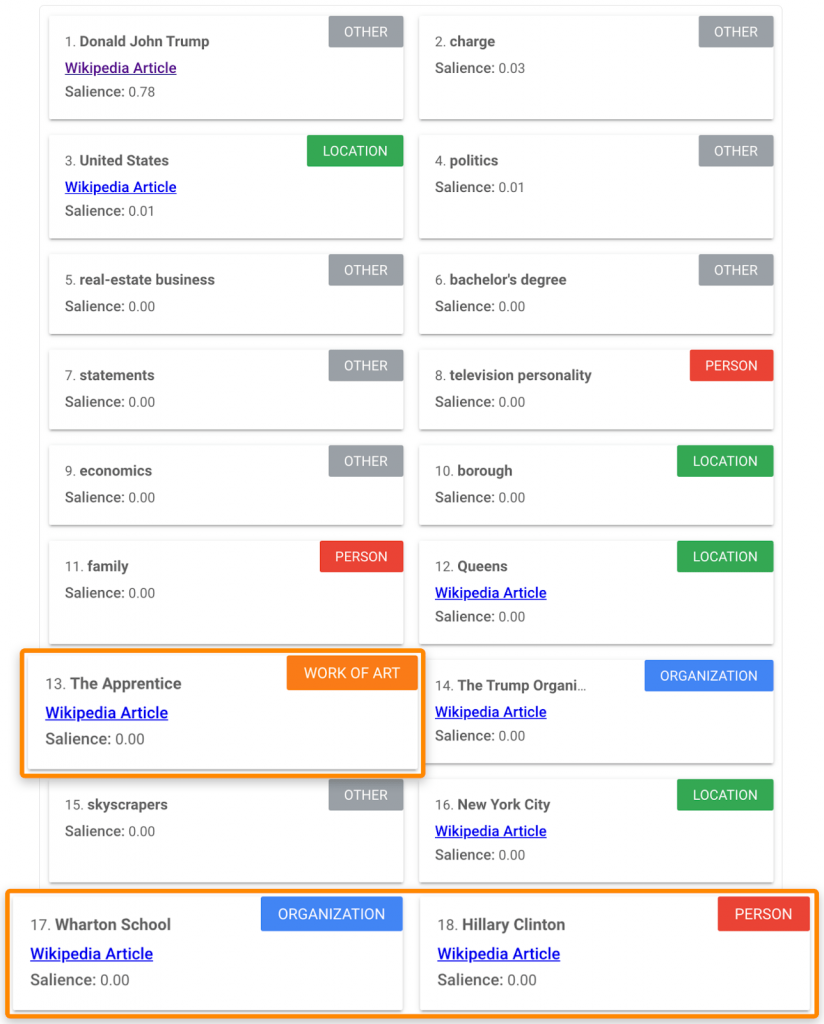
9. Воспользоваться Google’s Natural Language API
Вставьте текст со страницы с самым высоким рейтингом в демонстрационную версию Language API. Ищите релевантные и потенциально важные сущности, которые вы могли пропустить:
Заключение
Ключевых слов LSI не существует. Но есть слова, фразы и сущности, которые связаны с семантикой. Они способны повысить рейтинг страницы в поисковой системе.
Убедитесь, что вы используйте их там, где они действительно нужны. В некоторых случаях это может означать добавление нового раздела в ваши статьи.
Например, если вы хотите добавить слова и сущности вроде «импичмент» и «комитет внутренней разведки» к статье про Дональда Трампа, для этого потребуется несколько разделов с отдельными подзаголовками.



